Welcome to this series of articles about testing! It will be co-written with Benoît Maurice, colleague and friend for over 8 years now.
As TDD practitioners, we cannot ignore the major daily activities that are writing and maintaining tests. Today, we do not think it is desirable nor tenable to ignore this topic in a professional development context. There may be exceptions but we haven’t experienced any.
While the focus is often on coverage or speed, the readability and cleanliness of test code sometimes fall by the wayside. For example it is not uncommon to see test classes containing more than 20 tests while putting 20 methods in a class will appear aberrant.
That’s why, following on from what we have learned in this field, we are going to try and offer our opinion on how to write meaningful tests. We will be using C# as an example but the approach can probably be applied to any programming language.
Test granularity : the familiar pyramid model
First of all, let’s take a look at the type of tests we want to write. We started, as many do, with the famous test pyramid. It has a base with lots of automated unit tests, a few automated integration tests and manual end-to-end tests. Representations may vary but the idea is that you need lots of small, quick unit tests to cover your code base, while leaving the responsibility of checking consistency to wider-scoped tests.
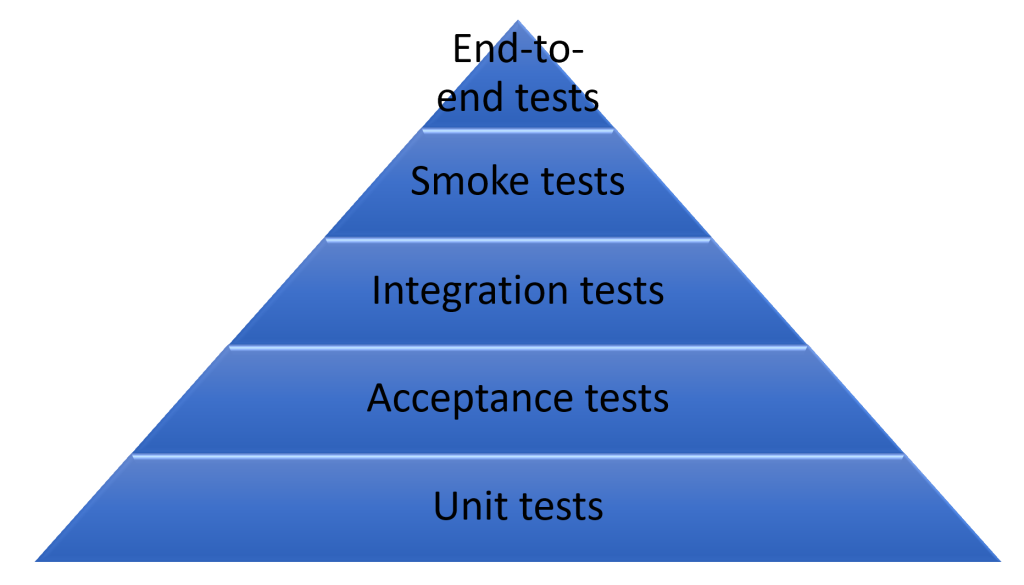
Questioning the model and introducing the authors
About Guillaume
Thanks to Thomas Pierrain, with whom he had the good fortune to work for a year and a half, Guillaume was able to challenge this somewhat fixed vision by understanding the value of acceptance testing: “coarse-grained” tests that start from the application or component entry point, stub or mock the infra-layer exit points (network or disk calls, database connections, etc.) and exit via the application exit point. This way, all layers are tested without stopping at a single method or class while avoiding the cost and fragility of connecting to external services.
About Benoît
As for Benoît, after almost 2 years as a coach explaining the test pyramid, he felt there was probably more to it than that. Although quick to write and reliable, the tests at the bottom of the pyramid seemed to be giving the coached teams trouble: purely technical tests, unreadable tests and tests that test a stub. Teams got lost in implementation details, refactoring became laborious and eventually fell by the wayside, creating a vicious circle. Each test was a copy-paste of the previous one with only a changed title. Stubs were kept without questioning why they existed in the first place. The test turned green. Sonar gave a good score. After dropping his coaching hat to return to a dev role in a team at a major French bank, Benoît discovered another way of approaching the pyramid by keeping bottom-of-the-pyramid testing only for critical components and focusing on the center of the pyramid through acceptance testing. By joining forces with Guillaume, they were able to perfect this idea together and go one step further in the idea of putting “coarse-grained” testing at the heart of the testing strategy.
Acceptance tests > unit tests ?
We will not dwell on this practice, to which Thomas has devoted 2 full articles: here’s the first and here’s the second. Thomas has also given several talks on the subject, including the one linked in these articles.
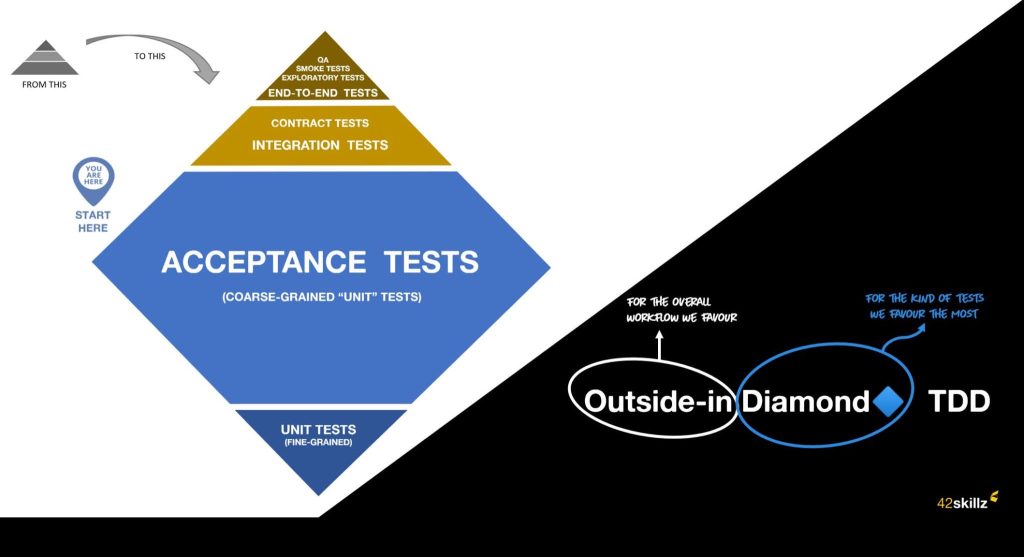
The problem with this type of testing is that, in a large project, the boilerplate needed to instantiate the various layers will be heavy and complex. We expect this because we will initially tend to reflect the complexity of the production code in our test code.
Case study: book sales site
Overview of the catalog feature
To illustrate in concrete terms the various points raised in this series of articles, we will use the fictitious case of a book sales site, in particular the “catalog” brick. This feature is characterized by a page on which you can list all the books in stock. For each result the page displays the following items:
- author’s name,
- number of pages,
- price,
- number of copies in stock,
- readers’ ratings via a third-party site (in our case, a fictitious “BookAdvisor” site).
Architecture and projects breakdown
We are in charge of the backend of this site and expose a RESTful API that returns data in JSON that the frontend will use.
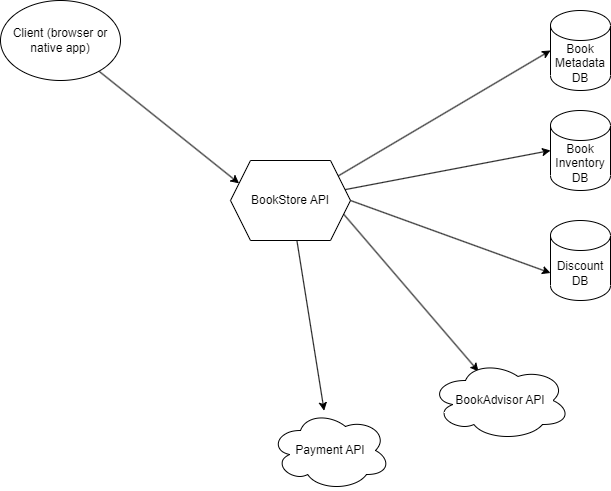
You can find the code in C# (.Net Core, Blazor for the front-end) on this GitHub repo. We use a hexagonal architecture with the domain in the center of the hexagon, the API on the “left side” of the hexagon and the infra (access to databases and third-party APIs) on the “right side”. Projects are broken down as follows:
- BookShop.api: exposes endpoints via controllers broken down by business context (catalog, pricing, checkout) and boilerplate for the server side. Left side of the hexagon.
- BookShop.domain: contains the business code: model, rules and interfaces (ports) enabling adapters to connect to the domain.
- BookShop.infra: adapters that connect to the outside world either via database connections or via HTTP clients to third-party services. For the sake of simplicity, we have hardcoded the databases.
- BookShop.shared: model shared between back and front.
- BookShop.web: front-end code for illustrative purposes only; we will not be testing it in these articles.
How do you test the API?
The sheer number of unit tests would quickly overwhelm us. Not to mention the boilerplate we would have to set up for each test and the impossibility of testing the interactions between the various layers of our stack.

via BetterCallMarco on Twitter.
We are going to start with real business scenarios and write tests covering the entire code path corresponding to each one, with the exception of external calls (network I/O, etc…).
In the next article, we will discuss how we started with simple builders to outsource the technical plumbing of creating our API stack without cluttering up the tests themselves.