On a souvent vu passer cette citation de Mark Zuckerberg « Move fast and break things ». Il est bon de rappeler que ce qui était autrefois la devise de Facebook est devenue « Move fast with stable infrastructure » en 2014…
Mais concrètement, ça signifie quoi « aller vite » ? Peut-on et doit-on accélérer en informatique ? Dans quel contexte est-ce acceptable et dans quel autre non ?
Ne pas confondre vitesse et précipitation
Peut-on imaginer livrer en production n’importe quand et n’importe comment ? Certes, les fonctionnalités arriveront vite mais ne risque-t-on pas de mettre en péril la production ? Si les clients n’arrivent pas à se connecter à nos sites 60% du temps, le chiffre d’affaires ne sera pas fameux.

En effet, en changeant de devise, Facebook met le doigt sur un point important : aller vite oui, mais le faire en toute sécurité c’est mieux ! Et de préférence en maîtrisant ce que l’on fait. Cependant, certaines organisations pensent qu’être en sécurité signifie mettre en place de longs et coûteux process de vérification, en ne livrant en production qu’avec parcimonie et en faisant passer chaque changement scrupuleusement par plusieurs personnes voire plusieurs équipes et comités de changement.
Mais tout cela est-il bien performant ? Le Time To Market (TTM) s’en trouve forcément négativement impacté et chaque nouvelle fonctionnalité d’autant plus retardée. Et est-ce bien plus sécurisé après tout ? En fait, il faudrait pouvoir mesurer tout ça.
Accelerate
En 2018 est sorti un petit livre qui a fait beaucoup de bruit : Accelerate, par Nicole Forsgren, Jez Humble et Gene Kim.

Il a eu un écho très positif car c’est un des rares ouvrages à faire une étude rigoureuse et quantitative sur la productivité des pratiques autour des projets informatiques. Le travail est colossal (et est répété tous les ans) et très bien synthétisé dans ce livre.
Les études dans Accelerate montrent que les organisations qui avaient une excellente performance avaient un avantage compétitif très net, une meilleure satisfaction client et une meilleure qualité de produit.
Je ne vais pas reprendre tout son contenu (je vous encourage plutôt à vous le procurer) mais j’aimerais revenir sur les points principaux.
Définitions et premières constatations
Pour éviter les malentendus, voici quelques définitions autour de quelques termes ou expressions qui reviennent souvent dans la discussion.
Performance
DORA metrics
Quand on parle de performance pour une équipe ou une organisation dans le domaine logiciel, on parle de quoi ? J’ai parfois l’impression que c’est un peu comme pour la productivité, tout le monde en parle mais sans définition précise ou chiffres à l’appui. Ça tombe bien, dans Accelerate il y a 4 points mesurables (les « 4 Accelerate metrics » ou « DORA metrics ») qui sont utilisés :
- « Lead time for change« , pas très éloigné du TTM, qui représente le temps qu’il faut à une modification entre le moment où elle est demandée et le moment où elle arrive en production.
- La fréquence de déploiement, c’est-à-dire combien de fois le code est déployé en production (par semaine, par mois, etc…).
- « Mean time to restore » : le temps moyen entre le moment où un bug (code ou infra) est repéré et le moment où il est corrigé en production.
- « Change failure rate » ou « taux d’échec des changements », en gros quel pourcentage des modifications de code résultent en bugs ? Bref, le taux de régression.
Implications
Ça signifie quoi concrètement ? Les études dans Accelerate montrent que les organisations qui avaient une excellente performance avaient un avantage compétitif très net, une meilleure satisfaction client et une meilleure qualité de produit que les organisations qui avaient une performance moins élevée.
Cela implique notamment que les organisations performantes livrent rapidement et fréquemment. Cela permet ainsi de réduire le TTM et de répondre rapidement aux bugs.
D’autre part, la stabilité et la non-régression sont assurées par de nombreux tests qui sont rejoués en amont de la livraison. Et pour que cela aille vite, il faut que ces tests soient automatiques et bien pensés. Cela contribue aussi à casser le « mur de confusion » entre dev et ops, où les uns sont payés pour modifier et ajouter des fonctionnalités là où les autres sont missionnés pour garder une production stable (vous vous souvenez de la phrase d’intro de Zuckerberg ?).
Culture
On entend souvent parler de « culture d’entreprise ». Là encore, bien souvent l’expression est floue donc les auteurs d’Accelerate ont pris comme référence le modèle de Ron Westrum qui dégage 3 catégories de culture :
- Pathologique : la culture du pouvoir (pour ma part je parlerais plutôt de tyrannie mais bon 😅).
- Bureaucratique : la culture de la règle.
- Générative : la culture de la performance.
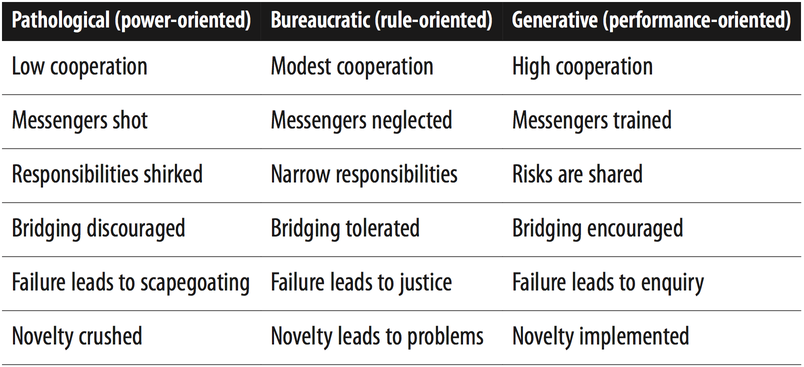
Sans surprise, les organisations les plus performantes ont développé une culture générative qui favorise la performance.
Comment améliorer la performance ?
Si on repart des constats précédents, il y a plusieurs points qui peuvent s’articuler afin de fournir une performance optimale :
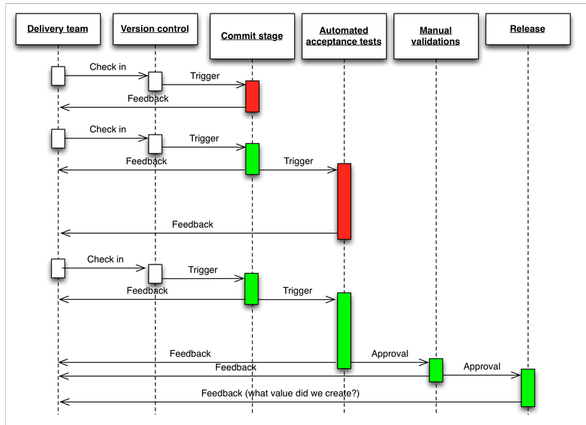
Pouvoir détecter les problèmes rapidement et en amont pour fournir un correctif rapide et avec impact minimal. Autrement dit, le « fast feedback ». Cela passe par des tests automatiques rejoués en local, des tests à plus large échelle rejoués lors d’une PR ou du déploiement (smoke tests, contract tests), mais aussi tout simplement par valider vos propres changements déployés sur une environnement de test.
Découper chaque tâche (user story, bug…) en petits incréments pour livrer plus rapidement et apporter de la valeur rapidement tout en restreignant les impacts.
« Computers perform repetitive tasks, people solve problems » donc on automatise les tests au maximum tout en simulant de véritables scénarios métier, on évite au maximum les interventions manuelles et on réserve notre temps de cerveau pour là où il y en a besoin. Comme je le dis souvent « en tant que dev, notre travail consiste principalement à automatiser des tâches pour les autres, donc facilitons-nous le travail et commençons par automatiser nos propres tests ».
De même pour tout ce qui est dépoiement et infrastructure, on automatise de façon à limiter ou éviter les risques opérationnels liés à des opérations manuelles. Là aussi tout est dans un outil de versioning afin que ce soit répétable et prédictif.
Utiliser une approche DevOps impliquant une reponsabilité partagée : on n’a pas fini son job quand le code est mergé. Pour reprendre une autre citation des GAFAM : « you build it, you run it » (Amazon, 2016). Ça marche aussi dans l’autre sens, côté ops quand la prod est en vrac c’est pas nécessairement la faute des devs (autre mantra bien connu : « it’s always DNS » 😁).
Enfin, avoir une démarche d’amélioration continue : on se remet en question régulièrement, on cherche toujours à améliorer le boulot de chacun et de l’équipe en particulier. S’arrêter sur des pratiques et ne plus en bouger, c’est l’assurance de ne plus pouvoir s’adapter au changement quand il arrivera. Une très bonne alliée pour se remettre en question est la diversité : avoir plusieurs profils hétéroclites permet d’avoir plusieurs points de vue différents et d’appréhender plusieurs expériences.
Ces points fondent les principes de la Continuous Delivery.
Impacts concrets
Il y a moins de bugs donc les équipes passent plus de temps sur les nouvelles features qu’à corriger des bugs ou à faire des réunions de crise sur des problèmes critiques non vus.
On a des tests automatisés qui sont rejoués plusieurs fois avant mise en production (en local, sur l’usine de build, avant le déploiement, après déploiement, etc…) donc les équipes ne perdent pas de temps à tester manuellement tous les scénarios de base, impactés ou non.
On livre des petites modifications donc les équipes connaissent moins de « deployment pain » : moins de stress, moins de hotfixes ou modifications faites dans l’urgence, pas de process/check lists interminables. Et comme les impacts sont maîtrisés, avec la bonne infrastructure, on peut souvent livrer à des horaires raisonnables, c’est-à-dire en pleine semaine et en pleine journée.
Bien souvent, les problèmes de déploiements viennent de soucis en amont : tests fragiles, architecture très couplée avec beaucoup de dépendances inter-équipes ce qui implique des livraisons synchrones, manque de visibilité sur les problèmes de prod, déploiements manuels (tout ou partiel) avec risque d’erreur ou d’oubli, silos entre ops, sys admins, QA, devs… donc on a des soucis de communication et de réactivité. Bref la liste est longue !
Côté produit et management, on n’a plus l’impression de perdre la main : les équipes techniques livrent régulièrement, ce qui permet de tester et faire des feedbacks rapidement et de modifier l’orientation du projet au gré des retours. Les changements d’avis ne sont plus punitifs et mal perçus, la réflexion n’est pas pénalisée, donc c’est plutôt bon pour le produit !
Au final, si on a plus de contrôle, moins de stress, moins de process rébarbatifs, plus de temps sur les nouvelles features… vous pensez pas qu’on est mieux ? 😊 Et du coup on a moins de turn over : tiens, encore une caractéristique que l’on trouve dans les organisations qui performent mieux.
À suivre…
Maintenant qu’on a défini les contours de notre discussion et que nous en avons vu les principaux concepts et impacts, quels sont les moyens concrets à mettre en oeuvre pour accélérer dans notre organisation et notre environnement professionnel ? On verra ça dans le prochain article !

Software developer since 2000, I try to make the right things right. I usually work with .Net (C#) and Azure, mostly because the ecosystem is really friendly and helps me focus on the right things.
I try to avoid unnecessary (a.k.a. accidental) complexity and in general everything that gets in the way of solving the essential complexity induced by the business needs.
This is why I favor a test-first approach to focus on the problem space and ask questions to business experts before even coding the feature.
