
Dans la première partie, nous avons vu les concepts exposés dans le livre Accelerate et les mesures mises en place pour calculer la performance d’une organisation. Nous allons dans cet article nous intéresser aux actions concrètes pour améliorer ces performances. Bien évidemment, il ne suffit pas d’avoir une usine de build et de se dire « ça y est, on fait de la CI/CD 😎 » ! Donc passons en revue diverses pratiques qui rendent la Continuous Delivery possible, à la fois au niveau technique pour les développeurs mais aussi au niveau des managers et des expert·es produit.
Pratiques techniques
Le versioning
En premier lieu, et c’est peut-être la pratique la plus répandue, il faut tout versionner (dans Git ou ce que vous voulez). C’est-à-dire le code, mais aussi la configuration, l’infra (« GitOps« ), etc… L’idée derrière est d’avoir une référence en laquelle tous les acteurs peuvent avoir confiance.
À noter aussi que le contenu versionné doit, dans la mesure du possible, être auto-suffisant : on descend le repository, on le builde, on le lance, tout marche sans action manuelle.
Un autre facteur pénalisant grandement la performance des équipes est la stratégie de versioning. Par exemple, lorsqu’on utilise des feature branchs ou git-flow (dont le créateur a admis il y a plus de 4 ans que ce n’était pas un bon choix pour tout ce qui est Continuous Delivery), il y a un délai non négligeable et variable selon les organisations entre le moment où le code est pushé et le moment où il est effectivement accepté dans la branche principale.
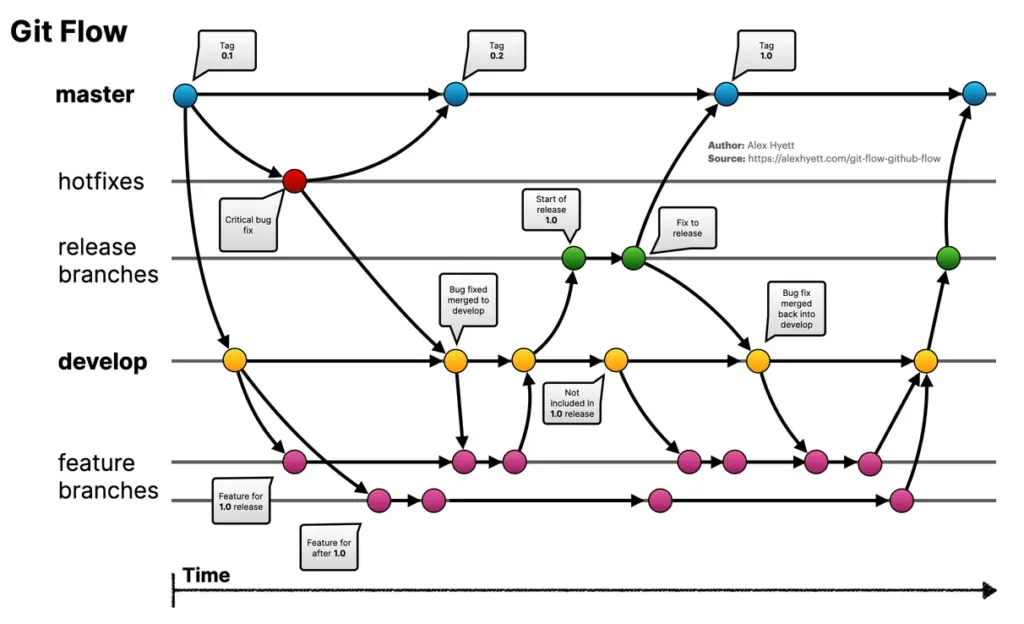
Une bonne pratique mentionnée par eXtreme Programming par exemple est de faire du pair programming (voire mob/ensemble) et de livrer directement sur la branche principale. On parle alors de trunk-based development, une technique que j’ai pu tester à plusieurs reprises avec succès.
Des tests automatisés fiables avec des données réalistes
Un des pires réflexes c’est de relancer un build en erreur parce qu’on ne comprend pas pourquoi un test a planté.
Ensuite, il faut des tests automatiques fiables. C’est-à-dire qu’on couvre tout le scope fonctionnel sans avoir de test « flaky », qui échouent aléatoirement. Un des pires réflexes c’est de relancer un build en erreur parce qu’on ne comprend pas pourquoi tel test a planté puis, comme par magie, ça passe. Comme on le dit depuis le début, on veut quelque chose de répétable et de fiable ; l’incertitude liée à des plantages aléatoires fait perdre beaucoup de confiance à tout le monde.
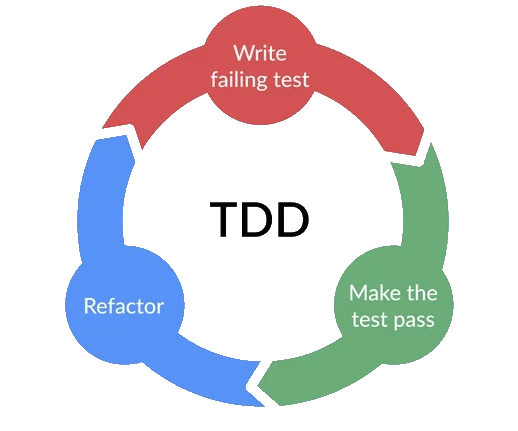
Idéalement, les tests sont écrits en TDD. Je ne vais pas revenir sur la définition ni dresser la liste exhaustive des bienfaits de TDD, je soulignerai juste qu’écrire les tests dès le départ permet de se poser les bonnes questions en amont, de faire un design plus réfléchi, de s’assurer que le scénario qu’on va implémenter sera testé et surtout de ne pas avoir à lancer l’appli à la main à chaque fois qu’on modifie 2 lignes.
Toujours concernant les tests et, plus globalement, les environnements hors production, il est souhaitable d’avoir des données qui correspondent le plus possible à ce qu’il y a en prod. Par exemple en faisant des dumps réguliers de bases de données ou en faisant des parallel runs avec de la gestion d’événements pour répliquer le comportement de la prod en direct.
Dans les tests, cela veut aussi dire éviter de mettre des valeurs bidons comme « toto » ou triviales (un seul élément dans une liste, etc…). Nous avions mentionné la technique du fuzzing avec Benoît dans la série d’articles sur les tests et coupler cette technique avec l’utilisation de données issues de la prod peut être un très bon remède à ce problème courant.
La sécurité
Enfin, un dernier point qui, bien trop souvent, fait office de 5ème roue du carrosse : la sécurité. On a tendance à repousser, négliger voire carrément éviter toute réflexion autour de ce sujet pourtant central. Je ne sais pas vraiment pourquoi c’est le cas ; peut-être parce que ce n’est pas un sujet « métier », que c’est vu comme un centre de coûts avant tout, mais toujours est-il que la sécurité est le parent pauvre de l’IT dans beaucoup d’organisations. Il est donc primordial de poser le sujet sur la table dès le début de chaque projet, avec des expert·es dédié·es et qui en savent beaucoup plus que la plupart des développeurs lambdas (et c’est bien normal).
Pratiques de management
Un·e manager ne peut pas intervenir directement car son rôle n’est pas technique.
Du point de vue managérial, tant sur le côté humain que sur la gestion de projet, il y a plusieurs leviers qui peuvent être activés. Un·e manager ne peut pas intervenir directement car son rôle n’est pas technique. Par contre, ses qualités de motivation, de facilitation et de support sont extrêmement précieuses et seront déterminantes quant à l’orientation prise sur un projet.
Il faudra également investir dans l’amélioration continue avec non seulement des rétros qui débouchent sur des actions concrètes, mais aussi un budget formation (cela peut inclure les conférences, pensez-y, les RH sont toujours intéressées par des moyens simples d’utiliser le budget formation), du temps pour expérimenter, des talks en internes pour le partage d’expérience, prévoir des journées ou des hackathons « anti-irritants » où l’équipe peut tacler des sujets pénibles récurrents par exemple.
Méthodologie : de la fluidité et de la communication
Il est recommandé d’être dans un état d’esprit orienté « flux », en s’inspirant par exemple de Kanban ou du Lean et plus particulièrement à tout ce qui touche aux limites de travail en cours (Work In Progress). Le but est d’éviter d’accumuler des tâches « en cours » sans jamais les finir et de se concentrer au contraire sur ce qui bloque ou retarde la finalisation. Le mantra « stop starting, start finishing » va dans ce sens. En éliminant les points bloquants ou lents, tout le process est fluidifié.
Dans la même veine, tous les process de validation manuelle, type Change Approval Board (CAB) où plusieurs personnes de différentes équipes se réunissent à intervalles réguliers afin de valider manuellement chaque changement, sont à proscrire. Ils préviennent rarement les problèmes (puisque les intervenants ne connaissent en général pas les sujets abordés dans le détail) et ralentissent énormément les livraisons. En les supprimant, on reste dans l’optique du « fast feedback » et on se permet aussi de livrer des correctifs rapidement sans attendre le prochain CAB.

Pousser l’information pour donner de la visibilité
Autre sujet : les « points de synchro » et autres réunions plus ou moins régulières pour permettre aux devs, aux ops, aux managers et au métier de faire le point pour savoir où on en est. Là, le plus simple est à la fois d’utiliser des bons outils (par exemple des dashboards permettant aux interlocuteurs non techniques d’avoir de l’info sans tomber dans les détails, comme le nombre de tickets traités ou restants, combien de % de telle feature ou de tel epic est terminé, etc…) et de pousser l’information régulièrement. Je pense notamment aux personnes côté technique : quand une tâche est terminée ou qu’elle connaît un problème structurant, il est important d’envoyer un mail ou un message instantané pour communiquer auprès de toutes les parties prenantes. Cela permet au management et au métier de déstresser et d’avoir de la visibilité, ça évite les points de synchro (ou au moins qu’ils soient trop longs) et cela fait nettement redescendre la pression pour tout le monde. Imaginez si votre facteur attendait une date fixe (ex : tous les jeudis) avant de vous donner votre courrier ou vos colis ; vous préfèreriez probablement qu’on vous livre dès que possible plutôt que d’attendre une date arbitraire. C’est pareil dans le dev, livrez quand vous pouvez et informez-en tout le monde.
Dans le même ordre d’idée, monter des partenariats avec les managers des autres équipes peut s’avérer extrêmement payant sur le moyen/long terme. En tenant les engagements ou en prévenant si des problèmes surviennent, en étant prévisible et fiable, on va nouer des alliances solides qui iront dans l’intérêt du produit. Attention en revanche à ne pas confondre prédictabilité et prendre ses désirs pour des réalités : les estimations sont par essence fausses et ne peuvent déboucher sur un planning fiable.
Instaurer une culture de la performance

D’autre part, cela semble aller de soi mais la culture du blâme est à proscrire. S’il est important d’éviter les erreurs, il est encore plus crucial d’apprendre de celles qui arrivent. Et un·e développeur·euse mis·e au ban d’une équipe pour avoir fait des erreurs pourra avoir un ou plusieurs de ces comportements : se braquer ou se renfermer, perdre en motivation, arrêter de prendre des initiatives, se désengager, quitter l’équipe ou l’entreprise, essayer de cacher d’autres problèmes, etc… liste non exhaustive. Et donc il faut se poser la question, au-delà du comportement humain, de l’intérêt pour le produit et l’organisation.
Il est plus sain d’adopter une posture d’ouverture face aux problèmes, par exemple « chouette, un bug ! » comme aimait à le dire un de mes précédents managers. En effet, un bug signifie qu’un scénario n’est pas couvert, soit parce qu’il manque simplement un test automatique, soit parce que les expert·es métier ne l’ont pas cerné. Dans tous les cas, on va pouvoir corriger notre fonctionnement et améliorer notre produit. Cela créera un cercle vertueux qui promouvra l’innovation au sein de l’organisation.
(Photo par LARAM via Unsplash)
De l’autonomie des collaborateurs
Un autre axe qui devrait paraître évident mais qui ne l’est pas forcément : il faut laisser les collaborateurs choisir leurs outils. S’il est compréhensible de vouloir déployer une politique à l’échelle de l’organisation (ex : cloud plutôt qu’on-premise), il faut pouvoir laisser de la latitude à vos équipes quant à leurs outils de travail. Cela peut aller de l’environnement de travail (PC Windows, Mac ou Linux ?) aux conditions (organisation du télétravail…) en passant par les droits d’accès ou d’installation de logiciels. Je ne compte plus les entreprises où j’ai travaillé où ReSharper n’était pas fourni et encore moins NCrunch. Vous voulez éviter à tout prix de mettre des bâtons dans les roues de vos collaborateurs, ne leur soyez pas ouvertement hostiles. De même, dans combien d’entreprises les demandes de droits d’accès ubuesques sont-elles obligatoires avant de pouvoir commencer à être productif ? Mise en place du PC, des environnements, des outils… « ah il me faut l’autorisation pour installer Docker », « ah maintenant je n’ai pas les droits de pousser mes devs sur tel repo Git », « le pipeline de build n’est pas optimisé mais je ne peux pas le modifier moi-même il faut que je demande aux DevOps », etc… C’est infernal et on ne sait pas qui ce genre de politique aide au final.

Pratiques produit
On tente des trucs et on avance
Au niveau des équipes métier ou produit (expert·es métier, PO, PM…), il y a plusieurs actions possibles. Déjà on peut commencer par avoir une approche incrémentale de type MVP (Minimum Viable Product) pour vérifier la viabilité d’une idée en la mettant à l’épreuve des retours clients puis itérer en priorisant pour ajouter le maximum de valeur. Pour ce faire et afin de s’assurer d’avoir des retours rapides, il est préférable de privilégier un découpage en scénarios métier, des sortes d' »unités fonctionnelles » atomiques. Une fois ces scénarios priorisés, on s’assure de bénéficier de la plus grande valeur ajoutée d’abord et d’avoir aussi un retour rapide, ce qui donne plus de visibilité. Le tout permettant aussi de corriger les plus gros problèmes plus rapidement et plus facilement.
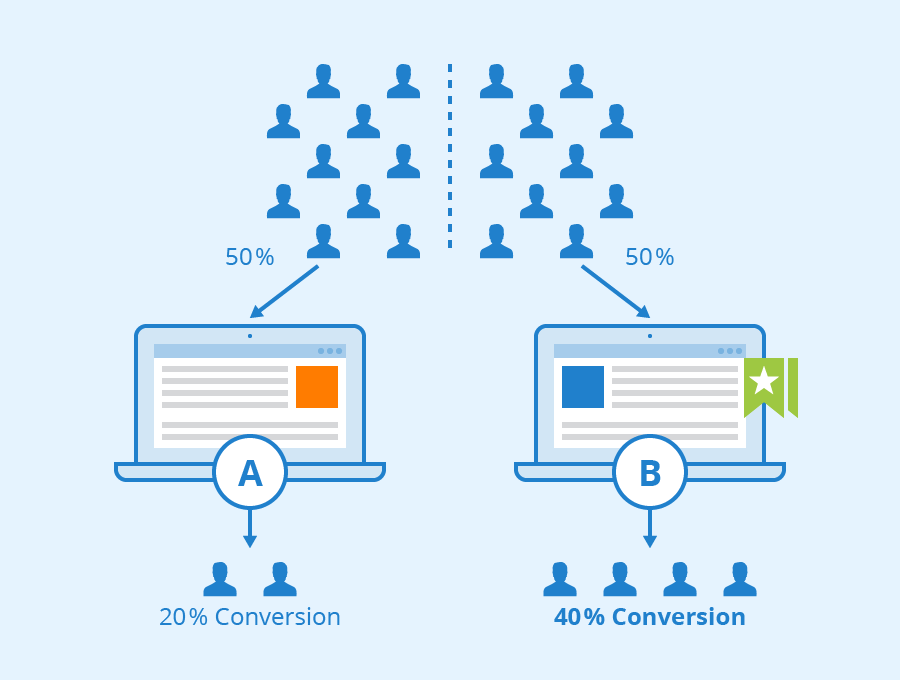
Dans cette même optique, l’esprit d’expérimentation doit être encouragé afin de pouvoir tester des fonctionnalités en production en toute sécurité. Par exemple en utilisant l’A/B testing ou les feature flags (en partenariat avec les équipes techniques) pour éviter les « big bangs » où tout est livré en même temps et permettre à la place des déploiements et tests plus sereins.
Faire comprendre le métier aux équipes techniques
D’autre part, comme ce qui est livré en production est la compréhension des développeurs, il est crucial d’être disponible afin de répondre à leurs questions, que ce soit de façon synchrone (réunions, appels…) ou asynchrone (mails, messagerie instantanée…). J’irais même plus loin en disant qu’il serait souhaitable de proposer plusieurs initiatives visant à améliorer la visibilité des équipes techniques quant au contexte métier : démonstration de là où la fonctionnalité attendue sera intégrée, clarification du jargon, vulgarisation de certains concepts, etc… que ce soit sous forme de réunion ou de support digeste pouvant être lu à tête reposée.
On a tout à gagner côté métier à fluidifier les interactions avec les équipes techniques. Contrairement au fameux « waterfall » du vieux cycle en V où tout est spécifié en amont, développé en tunnel et livré d’un coup à la fin, on a aujourd’hui les moyens de communiquer et livrer de façon simple et rapide. Au-delà des pratiques techniques, cela ouvre tout un univers des possibles pour le business.
Conclusion
Si on récapitule, il faut accélérer sur ce qui est automatisable et répétitif pour pouvoir ralentir sur ce qui apporte une réelle valeur ajoutée : la discussion, la réflexion, la remise en question. Il est essentiel de savoir se poser pour communiquer entre équipes techniques et équipes métier afin de mettre en place un vrai partenariat et non une relation « client-fournisseur » qui ne peut être que nuisible sur le long terme.
Mais bon, au final… vous n’avez pas l’impression qu’on dit des trucs plutôt intuitifs là ? « Discutez entre vous, automatisez ce qui est pénible et livrez quand vous avez fini ». Bravo l’expert ! Mais alors, pourquoi ce mode de fonctionnement est-il si peu répandu ? Pourquoi a-t-on toujours des « points de synchro », des estimations dans tous les sens, des sprints, des mises en prod peu fréquentes et où tout le monde est en stress ?
Pour terminer, je conseille la lecture de l’excellent site de Thierry de Pauw sur tout ce qui touche à l’intégration continue et ses pratiques. Thierry travaille sur ce sujet depuis de nombreuses années et a produit de nombreux articles et donné plusieurs conférences de qualité, à la fois sur la théorie et sur ses retours d’expérience. Ces travaux sont d’excellentes façons de pousser la réflexion et les actions après avoir lu Accelerate.

Software developer since 2000, I try to make the right things right. I usually work with .Net (C#) and Azure, mostly because the ecosystem is really friendly and helps me focus on the right things.
I try to avoid unnecessary (a.k.a. accidental) complexity and in general everything that gets in the way of solving the essential complexity induced by the business needs.
This is why I favor a test-first approach to focus on the problem space and ask questions to business experts before even coding the feature.
