En avril 2023, lorsque je travaillais pour un groupe hôtelier français, certains indicateurs métier nous ont amené à penser que la performance de nos APIs s’étaient dégradées. En me penchant sur le sujet, j’ai découvert plusieurs problèmes que je traiterai dans différents articles.
Aujourd’hui, je vais parler d’un point assez simple : comment paralléliser des appels indépendants à des dépendances externes.
Surveillance et mesures
Commençons par le commencement : les performances doivent être mesurées. Les sentiments peuvent constituer un point d’entrée intéressant puisqu’ils peuvent être le symptôme de réels problèmes. Mais ils ne peuvent pas ni ne doivent remplacer des mesures véritables. Il existe divers outils pour ce faire et dans mon cas j’ai utilisé Application Insights et des requêtes personnalisées dans Azure. J’ai aussi pris le temps d’écrire divers script k6 pour vérifier s’il y avait des régressions sur les 6 derniers mois (spoiler : il y en avait mais pas comme on le pensait à l’origine).
Premier problème détecté
Comme le laisse penser le titre de l’article, le premier problème que j’ai trouvé était que certains appels à nos dépendances étaient faits séquentiellement. Voici à quoi ressemblait le graphe d’appel dans Application Insights :

Ce n’est pas un problème en soi si ces appels sont dépendants les uns des autres mais ce n’était pas le cas ici. J’ai regardé le code et ai rapidement remarqué que la plupart de ces appels étaient indépendants.
Utilisons du code d’exemple !
Pour mieux illustrer ce que nous avions fait alors et éviter de compromettre le code de mon client, j’ai créé un projet d’exemple ici. Il s’agit d’une API incluse dans un projet Aspire, ce qui signifie qu’il y a de l’outillage natif (traçage, logs open telemetry…) et un container de base de données PostgreSQL.
Le but est de visualiser à quoi ressemblent des appels séquentiels puis les comparer avec du code faisant ces appels en parallèle. Pour cet article, la durée de ces appels est déterminée aléatoirement (voir le code source).
Version séquentielle
Voici à quoi ressemble le code de la version séquentielle dans la méthode GetAvailabilities() :
var availabilities = await availabilityProvider.GetAvailabilities(new HotelId(hotelIdAsString), startDate, endDate);
if (!availabilities.Any())
{
return NoContent();
}
var roomIds = availabilities.Select(availability => availability.RoomId).ToArray();
var roomInformation = await roomInformationProvider.GetInformation(roomIds);
var roomPictures = await roomInformationProvider.GetPictures(roomIds);
var rateIds = availabilities.Select(availability => availability.RateId);
var rateInformation = await rateInformationProvider.GetInformation(rateIds);
var result = MapToAvailableRoomWithPriceList(availabilities, roomInformation, roomPictures, rateInformation);
return Ok(new AvailableRoomsWithPrices(result));Il y a 4 appels à des dépendances :
- Ligne 1 : appel principal pour récupérer les chambres disponibles de l’hôtel. Si on ne peut pas en trouver, on sort tout de suite (« early return ») ce qui est une bonne pratique d’un point de vue des performances (et de la lisibilité aussi si vous voulez mon avis).
- Ligne 9 : appel pour récupérer des informations concernant les chambres disponibles.
- Ligne 10 : un autre appel pour récupérer les URLs vers les images de ces chambres qui ne sont pas dans le même référentiel.
- Ligne 12 : dernier appel pour récupérer des informations sur les tarifs de ces chambres (annulable, remboursable, mentions légales, etc…).
Tout est séquentiel. Dans le cas du premier appel c’est normal puisqu’on ne peut pas vraiment agir tant qu’on ne sait pas quelles chambres sont disponibles et à quel prix.
Ce code nous donne les traces suivantes dans Aspire :


Les appels séquentiels sont faciles à repérer sur ce type de graphe. Quand vous vouyez ce type de « marches d’escalier », alors il peut être intéressant de regarder le code. Peut-être certains appels sont-ils indépendants les uns des autres et nous pourrons les paralléliser.
Version parallèle
OK donc maintenant on va pouvoir agir et améliorer le code. J’ai fait les modifications suivantes dans la méthode GetAvailabilitiesParallel() :
var availabilities = await availabilityProvider.GetAvailabilities(new HotelId(hotelIdAsString), startDate, endDate);
if (!availabilities.Any())
{
return NoContent();
}
var roomIds = availabilities.Select(availability => availability.RoomId).ToArray();
var roomInformationTask = roomInformationProvider.GetInformation(roomIds);
var roomPicturesTask = roomInformationProvider.GetPictures(roomIds);
var rateIds = availabilities.Select(availability => availability.RateId);
var rateInformationTask = rateInformationProvider.GetInformation(rateIds);
var (roomInformation, roomPictures, rateInformation) = (await roomInformationTask, await roomPicturesTask, await rateInformationTask);
var result = MapToAvailableRoomWithPriceList(availabilities, roomInformation, roomPictures, rateInformation);
return Ok(new AvailableRoomsWithPrices(result));Vous voyez comme les awaits ont bougé sur la même ligne et sont séparés des invocations de méthode async ? Je reviendrai plus tard sur cette syntaxe mais voici à quoi ressemble le code dans les traces d’Aspire :


C’est quand même mieux ! Il semble qu’on ait réussit à économiser près de 40% sur le temps de réponse ! Cependant, on va éviter de tirer des conclusions à partir de seulement 2 échantillons. Voyons comment nous pouvons en rassembler plus afin d’obtenir des chiffres plus fiables.
Automatiser les appels à notre API avec k6
En 2022, j’ai entendu parler d’un outil nommé k6. Je n’en avais pas eu besoin à l’époque mais quand les soucis de performances ont fait surface en 2023, je l’ai essayé.
Ce que j’ai fait est très similaire à ce que vous pouvez voir dans le script k6/perfs.js : effectuer N appels l’un après l’autre à chaque endpoint de l’API puis regarder les chiffres. Voici à quoi cela ressemble après 100 appels à chaque endpoint :
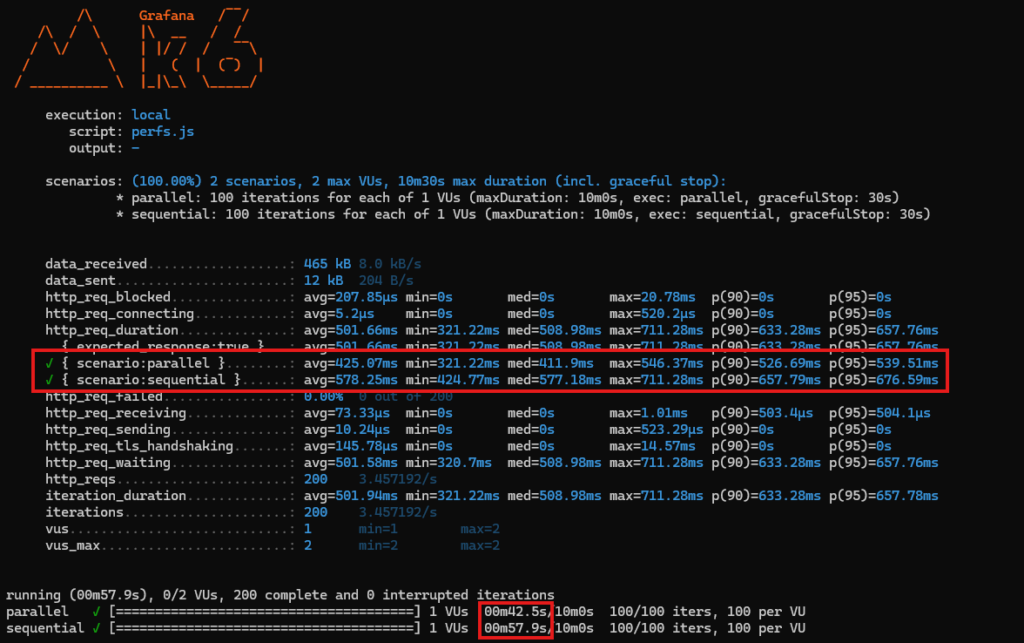
C’est un peu verbeux donc j’ai mis en évidence en rouge les chiffres qui nous intéressent ici. En gros, on peut voir que la durée moyenne est meilleure de 26%, la médiane de 28% et sur la p(95) de 20%. Gardez en tête que la latence des dépendances est simulé avec Random.Next() et suit sa distribution (qui doit être, je crois, uniforme mais je ne jouerais pas mon PEL là-dessus).
De plus, la durée totale est bien plus courte avec la version parallèle. Chaque gain se cumule pour finir par une amélioration de 26% qui correspond à l’amélioration sur la moyenne vue précédemment.
Conclusion
Bien évidemment, paralléliser les appels aux dépendances externes est souvent un « quick win ». Et on peut les repérer facilement avec un outil de surveillance basique. N’hésitez pas à jouer avec le code du repository car Aspire fournit un tel outil et permet aussi de simuler des dépendances ou d’inclure d’autres containers (ex : Redis, bases NoSQL, etc…).
Une dernière chose…
Je disais plus haut que nous reviendrions sur le code de la parallélisation, notamment cette partie :
var roomIds = availabilities.Select(availability => availability.RoomId).ToArray();
var roomInformationTask = roomInformationProvider.GetInformation(roomIds);
var roomPicturesTask = roomInformationProvider.GetPictures(roomIds);
var rateIds = availabilities.Select(availability => availability.RateId);
var rateInformationTask = rateInformationProvider.GetInformation(rateIds);
var (roomInformation, roomPictures, rateInformation) = (await roomInformationTask, await roomPicturesTask, await rateInformationTask);Que se passe-t-il ici ? On peut voir que les appels asynchrones aux dépendances ne sont pas attendus (« awaited ») immédiatement. Le truc c’est que les tâches sont créées et lancées dès que les méthodes asynchrones sont appelées. C’est souvent une grande source de confusion parmis les développeurs .Net. La plupart pensent qu’un Task.WhenAll() est nécessaire pour que les tâches soient effectivement lancées. Non, elles sont lancées directement quand les méthodes async sont appelées.
Ligne 7, j’ai fait un await pour toutes les tâches à la manière d’une déconstruction pour éviter le code suivant :
var roomInformation = await roomInformationTask;
var roomPictures = await roomPicturesTask;
var rateInformation = await rateInformationTask;Pour finir sur ce sujet, vous pouvez jeter un oeil à cette discussion sur Stack Overflow. Les esprits s’échauffent un peu ici et là mais gardez à l’esprit ce que j’ai dit : les tâches sont lancées dès que les méthodes async sont appelées. C’est aussi corroboré par le comportement et les graphes de notre API ci-dessus. Puis vous réaliserez que la réponse plébiscitée conseille d’utiliser Task.WhenAll() alors que c’est inutile en réalité. Et vous remarquerez aussi que le commentaire plébiscité pour cette réponse est aussi complètement faux. Si, après tout ça, vous ne voulez pas me croire, faites confiance à Stephen Cleary 😉

Toutefois, plus loin dans la discussion, Stephen soulève un point intéressant : un Task.WhenAll() explicite enlèvera toute confusion pour les développeurs moins expérimentés. D’où son utilité après tout. J’ai choisi de ne pas le faire dans ce code justement pour discuter de ce sujet dans l’article. J’espère que ça a été utile !

Software developer since 2000, I try to make the right things right. I usually work with .Net (C#) and Azure, mostly because the ecosystem is really friendly and helps me focus on the right things.
I try to avoid unnecessary (a.k.a. accidental) complexity and in general everything that gets in the way of solving the essential complexity induced by the business needs.
This is why I favor a test-first approach to focus on the problem space and ask questions to business experts before even coding the feature.