(Afin de ne pas surcharger cet article déjà un peu dense, nous supposons que vous êtes familier·e avec la notion d’adapter dans l’architecture hexagonale. D’autre part, nous utiliserons les terms « mock » et « stub » indifféremment car ça ne semble clair pour personne, comme le montre cette intéressante discussion sur StackOverflow. D’un point de vue purement technique, nous utilisons la librairie NSubstitute pour créer la plupart de nos mocks/stubs et NFluent pour les assertions de nos tests.)
Comme vu dans l’article précédent notre but est d’instancier le plus haut niveau de notre API, comme un endpoint notamment (dans notre exemple un controller), de passer les inputs nécessaires pour faire tourner un scénario métier réel et de tester la sortie de cet endpoint. Pour éviter les frictions et ne tester que notre code, on va alors stubber toute interaction avec l’extérieur :
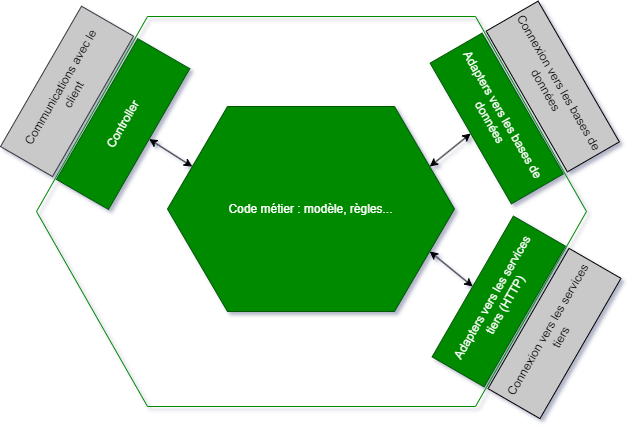
Selon les stacks techniques, instancier une API mais en stubbant certaines dépendances n’est pas chose aisée. De plus, dans la mesure où l’on veut réduire la technique au minimum dans un test qui est censé représenter un comportement métier, on va en premier lieu vouloir sortir cette plomberie (ou « boilerplate ») dans des mécanismes à part. Pour notre part, nous avons opté pour le pattern builder utilisant une API un peu « fluent », pour une meilleure lisibilité. Le but étant que, si jamais un·e expert·e métier devait lire le code, l’intention lui soit immédiatement compréhensible.

Écriture du test
Dans notre cas, nous allons commencer simplement en écrivant un test qui soit un peu naïf et ne semble pas trop lourd, par exemple en comptant le nombre de livres renvoyés par la méthode GET de la route api/Catalog. Un premier jet pourrait être :
public class CatalogControllerShould
{
[Fact]
public async Task List_all_books_when_called_on_GetCatalog()
{
const int numberOfBooksInCatalog = 3;
var controller = new CatalogControllerBuilder()
.WithRandomBooks(numberOfBooksInCatalog)
.Build();
var catalogResponse = await controller.GetCatalog("EUR");
Check.That(catalogResponse.Books).HasSize(numberOfBooksInCatalog);
}
}Le code du test est clair et lisible, le scénario est parfaitement identifiable.
C’est assez simple, pas trop de plomberie technique hormis l’appel à CatalogControllerBuilder, c’est parlant : on veut créer un CatalogController pour un catalogue comportant 3 livres aléatoires et on veut vérifier que l’appel à GetCatalog() renvoie le bon nombre de livres. On choisit sciemment un nombre inférieur à 5 ici car la pagination par défaut de notre site est à 5 livres. Baby steps ! Il faudra par la suite créer un test avec 6 livres ou plus pour tester que l’on pagine bien correctement.
Builder : premier jet et introduction au fuzzing
Évidemment, le code ne compile pas puisque le code du builder est absent. À quoi va-t-il bien pouvoir ressembler ? Là c’est un peu plus complexe. Déjà il va falloir créer le controller avec ses dépendances, mais aussi faire les stubs aux bons endroits. Mais surtout, il va falloir créer des livres de façon aléatoire. Le côté aléatoire est ici important : notre test ne porte aucun intérêt aux livres en eux-mêmes. On veut juste pouvoir les compter. On va donc les créer aléatoirement au lieu de, par exemple, les coder en dur : il s’agit ici d’une technique appelée le fuzzing. Pour implémenter cela, nous nous appuierons sur la librairie Diverse de Thomas Pierrain :
public class CatalogControllerBuilder
{
private readonly IFuzz _fuzzer = new Fuzzer();
private Book[] _booksInCatalog;
public CatalogControllerBuilder WithRandomBooks(int numberOfBooksToGenerate)
{
_booksInCatalog = Enumerable
.Range(0, numberOfBooksToGenerate)
.Select(_ => {
var randomIsbn = new ISBN.ISBN10(_fuzzer.GenerateInteger(1, 100), _fuzzer.GenerateInteger(1, 10000), _fuzzer.GenerateInteger(1, 1000), _fuzzer.GenerateInteger(1, 10));
var firstName = _fuzzer.GenerateFirstName();
var lastName = _fuzzer.GenerateLastName(firstName);
var authorName = $"{firstName} {lastName}";
var pictureUrl = new Uri(_fuzzer.GenerateStringFromPattern("http://picture-url-for-tests/xxxxxxx.jpg"));
return new Book(new BookReference(randomIsbn, _fuzzer.GenerateSentence(6), authorName, _fuzzer.GenerateInteger(10, 1500), pictureUrl), _fuzzer.GenerateInteger(1, 100));
})
.ToArray();
return this;
}
}Bon c’est un début mais ce n’est pas très lisible ! Un refactoring judicieux serait par exemple de faire une méthode d’extension à IFuzz pour générer des ISBN. On note aussi les angles morts implicites : on considère que chaque nom est au format « prénom nom » (ce qui est faux), on génère des entiers complètement aléatoirement pour fabriquer des ISBN alors que ce n’est peut-être pas correct (il faudrait demander à un·e expert·e métier) et on part du principe qu’on n’aura pas plus de 99 exemplaires d’un livre donné en stock. Donc on se met des œillères mais c’est un point de départ pour notre série d’articles 😉
Attaquons-nous à la méthode Build() maintenant, c’est elle qui va devoir gérer les dépendances ; là encore c’est un premier jet simplement pour faire compiler le code :
public CatalogController Build()
{
// spi ports are stubbed
var bookMetadataProvider = Substitute.For<IProvideBookMetadata>();
var inventoryProvider = Substitute.For<IProvideInventory>();
var bookAdvisorHttpClient = new BookAdvisorHttpClient(new HttpClient(new MockHttpHandler()));
// this port is not stub because of its dummy implementation
var bookPriceProvider = new BookPriceRepository();
// domain is created manually
var catalogProvider = new CatalogService(bookMetadataProvider, inventoryProvider);
// api adapter can be manually created since we have the domain and spi ports at hand
return new CatalogController(catalogProvider, bookPriceProvider, bookMetadataProvider, bookAdvisorHttpClient);
}Ici, MockHttpHandler est une classe qui dérive simplement de HttpMessageHandler et renvoie un HttpResponseMessage vide. Bref, ça compile mais évidemment ça plante au runtime : dès qu’on essaie de lire une donnée depuis un port ce dernier renvoie null puisque rien n’est « stubbé » actuellement.
Stubs
On a du code qui compile mais le test plante lamentablement en essayant de lire certaines données nulles. Appliquons-nous maintenant à faire des vrais stubs de façon à faire passer le test :
public class CatalogControllerBuilder
{
private readonly IFuzz _fuzzer = new Fuzzer();
private Book[] _booksInCatalog = Array.Empty<Book>();
public CatalogControllerBuilder WithRandomBooks(int numberOfBooksToGenerate)
{
_booksInCatalog = /* ... same code as above that generates books ... */
return this;
}
public CatalogController Build()
{
var bookMetadataProvider = StubBookMetadataProvider();
var inventoryProvider = StubInventoryProvider();
var bookAdvisorHttpClient = StubBookAdvisorHttpClient();
return /* create the domain & controller as before */
}
private IProvideInventory StubInventoryProvider()
{
var inventoryProvider = Substitute.For<IProvideInventory>();
inventoryProvider.Get(Arg.Any<IEnumerable<BookReference>>())
.Returns(callInfo =>
{
var requestedBookReferences = callInfo.Arg<IEnumerable<BookReference>>();
return _booksInCatalog.Where(book => requestedBookReferences.Contains(book.Reference));
});
return inventoryProvider;
}
private BookAdvisorHttpClient StubBookAdvisorHttpClient()
{
return new BookAdvisorHttpClient(new HttpClient(new MockBookAdvisorHttpHandler(_fuzzer))
{
BaseAddress = new Uri("http://fake-base-address-for-tests")
});
}
/* ... other stub methods matching the same pattern ... *
}On remarque que la structure est un peu lourde. Beaucoup de choses sont mélangées et un peu difficiles à distinguer.
C’est lourd mais pas très compliqué : on bouge la responsabilité du stub de chaque dépendance dans une méthode dédiée et on se débrouille avec ce qu’on a pour répondre correctement. La classe MockBookAdvisorHttpHandler pour stubber le comportement du client HTTP vers BookAdvisor est aussi assez simple :
internal class MockBookAdvisorHttpHandler(IFuzzNumbers fuzzer) : HttpMessageHandler
{
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
if (request.RequestUri is not null && request.RequestUri.AbsolutePath.StartsWith("/reviews/ratings/"))
{
var rating = Math.Round(fuzzer.GeneratePositiveDecimal(0m, 5m), 2);
var numberOfRatings = fuzzer.GenerateInteger(2, 20000);
return new HttpResponseMessage(HttpStatusCode.OK)
{
Content = JsonContent.Create(new RatingsResponse(rating, numberOfRatings))
};
}
return new HttpResponseMessage(HttpStatusCode.NotFound);
}
}Premières critiques
Bon ! Le test est maintenant vert ; le code complet est disponible sur le premier commit de la branche « builders ». Si on se pose un peu et qu’on prend du recul, faisons un rapide bilan en commençant par les points positifs :
- Le code du test est clair et lisible, le scénario est parfaitement identifiable, on n’a quasiment aucun code purement technique dedans.
- On a tous les bénéfices d’un test d’acceptance : on rejoue un scénario métier dans le cadre d’un appel complet à notre code hors couches basses. Avec des tests unitaires, il aurait fallu au moins 5 ou 6 tests différents pour le même scénario en stubbant plusieurs couches à chaque fois, sans garantie que chaque brique se comporte bien avec les autres.
- Il en découle qu’on couvre quasiment toute notre stack, à l’exception des couches basses comme IProvideInventory (qui est vraiment un peu simpliste dans notre exemple). Dans la réalité, sur un cas de repository interrogeant une base de données, on stubbera la connexion à la BDD plutôt que notre port et son implémentation.
- Le test est rapide (de l’ordre de 130 à 150 ms sur ma machine équippée d’un Intel Core i7 8700k).
En étant un peu plus critique, on remarque néanmoins que la structure paraît un peu lourde. Beaucoup de choses sont mélangées (gestion et création des dépendances, stub…) et un peu difficiles à distinguer. On imagine aisément que, si le code venait à se complexifier, le builder prendrait encore plus de poids. Notre builder reflète tout simplement la complexité de notre code de prod.
Améliorations
On peut alors imaginer plusieurs solutions :
- Déplacer la construction de chaque dépendance dans son builder attitré. On revient ici au principe de séparation des problèmes où chacun gère son périmètre. Dans notre exemple, cela consiste à avoir un
CatalogServiceBuilderqui gèrerait lui-même la construction de ses dépendances. - Utiliser des objets dédiés pour le fuzzing. Par exemple ici, au lieu d’utiliser directement l’objet métier
Book, on peut passer par un objet «BookSpecification» dont le but serait de proposer des paramèteres optionnels où chaque paramètre non spécifié serait fuzzé automatiquement dans le constructeur. - Rendre notre code de prod moins complexe ! Ça semble évident mais ce qui paraît être un problème est en fait un bon détecteur de code smell : si nos builders sont trop compliqués, c’est peut-être que notre code de prod l’est aussi et a besoin d’être simplifié. C’est une bonne occasion d’y réfléchir.
Essayons certaines de ces pistes en améliorant notre test : au lieu de compter simplement le nombre de livres retournés, on va vérifier que ce sont les bons livres qui sont renvoyés en regardant chaque propriété.
Nous n’allons pas détailler ici toute l’implémentation ; voici à quoi ressemble le test et, pour le reste (builders, etc…), il est possible d’aller sur le second commit de la branche builders et de voir par vous-même.
[Fact]
public async Task List_all_books_when_called_on_GetCatalog()
{
var fuzzer = new Fuzzer();
var books = new BookSpecification[]
{
new(fuzzer),
new(fuzzer),
new(fuzzer)
};
var controller = new CatalogControllerBuilder()
.WithBooks(books)
.Build();
var catalogResponse = await controller.GetCatalog("EUR");
Check.That(catalogResponse.Books).HasSize(books.Length);
// This because of the sloppy implementation of our BookPriceRepository :)
var uniqueBookPrice = new Price(8m, "EUR");
var expectedResponse = books.Select(book => new BookResponse(book.Isbn.ToString(), book.Title, book.Author, book.NumberOfPages, new RatingsResponse(book.AverageRating, book.NumberOfRatings), book.PictureUrl.ToString(), book.Quantity.Amount, uniqueBookPrice));
Check.That(catalogResponse.Books).IsEquivalentTo(expectedResponse);
}Critiques du code amélioré
Là encore, si l’on devait faire la critique de ce nouveau code, que pourrions-nous dire ?
- Le
CatalogControllerBuildera bien maigri ! 49 lignes contre plus de 80 auparavant. C’est un des premiers objectifs qu’on s’était fixés. - Chaque builder est bien responsable de ses propres dépendances. Le découpage est clair et, pour savoir où est stubbé un comportement, il suffit d’aller voir dans le builder correspondant.
- De même, la construction des objets métier (contenant toute la manipulation des fuzzers) est déléguée à des objets dédiés, les builders n’ont plus à s’en préoccuper.
- Les performances ne sont pas affectées.
Mais ces améliorations ont eu d’autres impacts, plus négatifs :
- Le test est maintenant plus technique, la faute au fuzzer qu’il a fallu remonter dans le test afin de pouvoir créer nos
BookSpecifications. Il est indispensable d’utiliser la même instance de Fuzzer ici afin de pouvoir reproduire en fixant un seed en cas de bug dû au caractère aléatoire du fuzzing. Donc en l’état actuel, on ne peut pas faire grand-chose sur ce point. D’ailleurs, notre test dans sa forme actuelle plante aléatoirement… à vous de débugger et trouver ce qui ne va pas 😉 (indice : c’est quand on génère un ISBN) - Par essence, la structure devient plus complexe puisque chaque dépendance a son builder. Nous n’avons pas eu à faire de builder pour les repositories qui sont ici simplistes, mais dans des cas plus concrets de repositories se connectant à des bases de données, il aurait fallu aussi un builder par repository afin de stubber chaque connexion à la base. Si le nombre de dépendances augmente, on va très vite se retrouver enseveli dans plusieurs couches de builders difficiles à comprendre et à maintenir.
- On a une dépendance partagée entre 2 builders, introduisant un couplage. Ici,
IProvideBookMetadataest utilisé à la fois parCatalogControlleretCatalogService. Comment doit-on faire dans nos builders ? J’ai choisi de faire 2 stubs différents, toujours dans l’esprit de cloisonner chaque stub là où il est utilisé, mais on s’éloigne du comportement du code de prod où la dépendance est déclarée avec un scope Singleton dansProgram.cs. Utiliser la même instance au niveau des stubs aurait du sens mais introduirait un couplage temporel au niveau des builders, ce qui complexifierait encore plus notre code.
Conclusion
Comme on le voit, en poussant un peu le périmètre des tests et en découpant notre plomberie technique, on se retrouve certes avec un découpage correct mais une complexité grandissante. Si notre code de prod comportait encore plus de dépendances, il serait vite difficile de s’y retrouver. Cependant, comme on le notait plus haut, cela souligne aussi que le code de prod mériterait un refactoring : est-il bien normal que notre CatalogController passe par un CatalogService dans un cas et attaque le BookMetadataProvider dans l’autre ?
Dans le prochain article, nous reviendrons en détails sur la situation réellement rencontrée sur le backend d’un site d’e-commerce où Benoît et moi avons travaillé : d’où nous partions, ce que les builders ont apporté et pourquoi nous avons choisi d’aller plus loin.

Software developer since 2000, I try to make the right things right. I usually work with .Net (C#) and Azure, mostly because the ecosystem is really friendly and helps me focus on the right things.
I try to avoid unnecessary (a.k.a. accidental) complexity and in general everything that gets in the way of solving the essential complexity induced by the business needs.
This is why I favor a test-first approach to focus on the problem space and ask questions to business experts before even coding the feature.