Bienvenue dans cette série d’articles sur les tests ! Elle sera co-écrite avec Benoît Maurice, collègue et ami depuis maintenant plus de 8 ans.
Écrire et maintenir des tests : en tant que praticiens du TDD, ce sont des activités quotidiennes majeures incontournables. Il ne nous paraît aujourd’hui pas souhaitable ni même tenable de faire l’impasse sur ces sujets dans un contexte de développement professionnel. Peut-être y a-t-il des exceptions, mais pour notre part nous n’en avons pas fait l’expérience.
Si l’on se concentre souvent sur la couverture des tests ou leur rapidité, la lisibilité et la propreté du code de tests sont parfois mises de côté. Il n’est pas rare de voir des classes de tests contenant plus de 20 tests par exemple, alors que mettre 20 méthodes dans une classe paraîtra plus facilement aberrante.
C’est pourquoi, suite à divers apprentissages dans ce domaine ces dernières années et en particulier ces derniers mois, nous allons essayer d’apporter notre opinion pour écrire des tests avec du sens. Nous nous appuierons sur des exemples en C# mais la démarche peut probablement s’appliquer à n’importe quel langage.
La granularité des tests
Le modèle connu de la pyramide
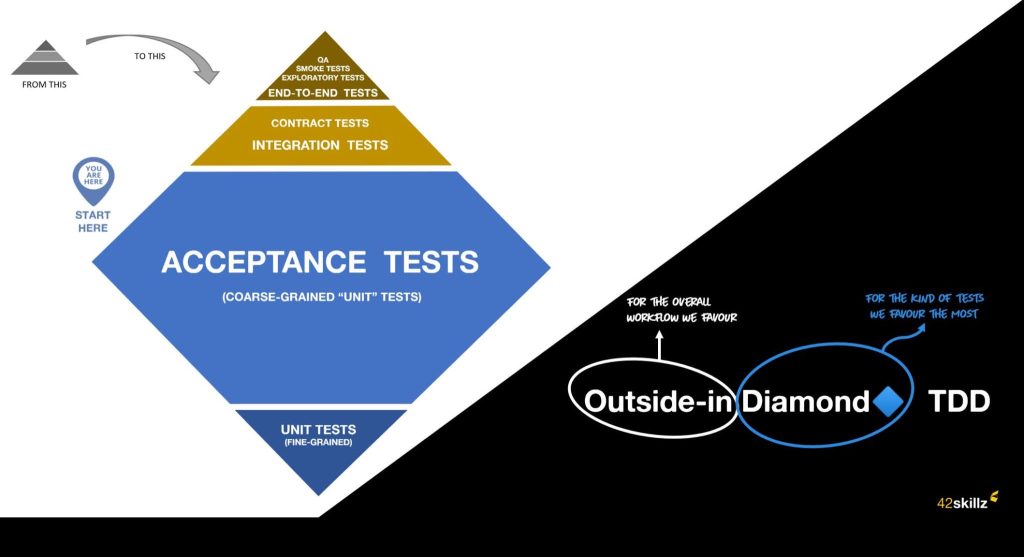
Avant toute chose, faisons un point sur le type de tests à écrire. On a commencé, comme beaucoup, avec la fameuse pyramide de tests : une base avec plein de tests unitaires automatisés, quelques tests d’intégration eux aussi automatisés et des tests end-to-end bien souvent manuels. Les représentations varient mais l’idée est de dire qu’il faut plein de petits tests unitaires rapides pour bien couvrir sa base de code tout en laissant la main à des tests avec un périmètre plus large pour vérifier la cohérence.

Remise en question et présentation des auteurs
Grâce à Thomas Pierrain avec qui il eu la chance de travailler pendant 1 an et demi, Guillaume a pu remettre en question cette vision un peu figée en comprenant l’intérêt des tests d’acceptance : des tests « gros grains » qui partent du point d’entrée de l’application ou du composant, stubbent ou mockent les points de sortie des couches d’infra (appels réseaux ou disque, connexions aux bases de données, etc…) et ressortent par le point de sortie de l’application. On teste alors toutes les couches, sans s’arrêter à une méthode ou un classe, tout en évitant le coût et la fragilité de se connecter à des services externes.
Le problème de ce type de tests c’est que, dans un projet un peu conséquent, la plomberie nécessaire pour instancier les divers services sera lourde et complexe.
Quant à Benoît, après presque 2 ans dans la peau d’un coach à expliquer la pyramide de tests, il sentait qu’il y avait probablement mieux à faire que ça. Bien que rapides à écrire et fiables, les tests du bas de la pyramide semblaient donner du mal aux équipes accompagnées : tests purement techniques, tests illisibles et tests qui testent un stub. Les équipes se perdaient dans les détails d’implémentation, le refactoring devenait laborieux et finissait par passer à la trappe, créant ainsi un cercle vicieux. Chaque test était un copier-coller du précédent dont on changeait juste le titre. Les stubs étaient gardés sans se poser la question de la raison pour laquelle ils existaient. Le test passait au vert. Sonar donnait une bonne note. Après avoir laissé tomber sa casquette de coach pour revenir à un rôle de dev dans une équipe au sein d’une grande banque française, Benoît découvrit une autre façon d’aborder la pyramide en ne gardant les tests du pied de la pyramide que pour les composants critiques et en mettant un accent sur le centre de la pyramide par le biais de test d’acceptance. En rejoignant Guillaume, ils ont pu ensemble parfaire cette idée et aller un tout petit peu plus loin dans l’idée de mettre les tests « gros grains » au coeur de la stratégie de tests.
Nous ne nous étendrons pas sur cette pratique à laquelle Thomas a consacré 2 articles complets (en anglais) : voici le premier et voici le second. Par ailleurs, Thomas a fait plusieurs talks sur le sujet, dont celui qui est en lien dans ces articles.
Le problème de ce type de tests c’est que, dans un projet un peu conséquent, la plomberie nécessaire pour instancier les divers services, repositories et j’en passe, sera lourde et complexe. Normal, puisque dans un premier temps on aura tendance à refléter la complexité du code de prod dans notre code de test.
Cas d’étude : site de vente de livres
Afin d’illustrer concrètement les différents points soulevés au long de cette série d’articles, nous allons utiliser le cas fictif d’un site marchand de vente de livres, notamment à la brique dite de « catalogue ». Celle-ci se caractérise entre autres par une page sur laquelle on peut lister tous les livres en stock et, pour chaque résultat, on affiche sur la page les items suivants :
- nom de l’auteur,
- nombre de pages,
- prix,
- nombre d’exemplaires disponibles en stock,
- la note par les lecteurs via un site tiers (dans notre cas, un site fictif « BookAdvisor »).
Nous sommes en charge de la partie backend de ce site et exposons une API plus ou moins RESTful qui renvoie ces données en JSON, exploitées ensuite par le frontend.
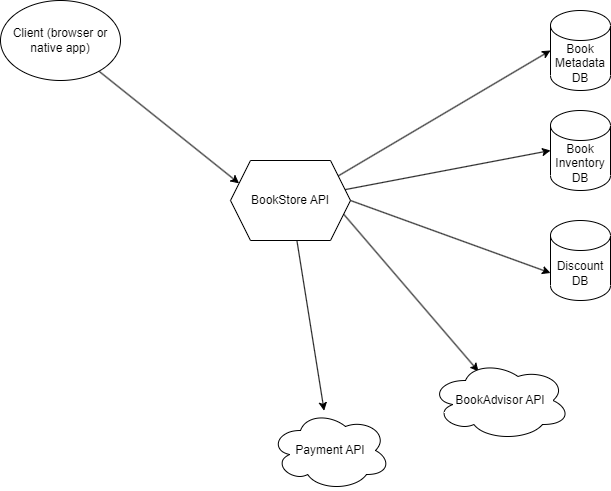
Le code en C# (.Net Core, Blazor pour le front-end) peut se trouver sur ce repo GitHub. On utilise une architecture hexagonale, avec le domaine au centre de l’hexagone, l’API sur le « côté gauche » de l’hexagone, et l’infra (accès aux bases de données et aux API tierces) sur le « côté droit ». Les projets sont découpés comme suit :
- BookShop.api : couche d’exposition des endpoints via des controllers découpés par contexte métier (catalogue, pricing, checkout) et boilerplate de la partie serveur. Côté gauche de l’hexagone.
- BookShop.domain : c’est l’intérieur de l’hexagone, le code purement métier : modèle, règles et interfaces (ports) permettant aux adapters de se brancher sur le domaine.
- BookShop.infra : les adapters qui vont se connecter à l’extérieur, soit via des connexions à des bases de données (par simplicité on a hardcodé les données ici), soit via des clients HTTP aux services tiers.
- BookShop.shared : modèle partagé entre le back et le front.
- BookShop.web : code front qui est là purement à titre d’illustration ; nous ne le testerons pas dans ces articles.
Comment réaliser les tests de l’API ? Avec des tests unitaires (ou TU), on se retrouverait vite submergés par le nombre, sans parler du setup à mettre en place à chaque test et de l’impossibilité de tester les interactions entre diverses couches de notre stack.

via BetterCallMarco sur Twitter.
On va donc partir de véritables scénarios métier et rédiger des tests couvrant tout le chemin de code correspondant à chacun, à l’exception des appels externes (I/O réseau, etc…).
Dans l’article suivant, nous verrons comment nous avons démarré avec des builders simples pour externaliser la plomberie technique de la création de la stack de notre API sans encombrer les tests en eux-mêmes.

Software developer since 2000, I try to make the right things right. I usually work with .Net (C#) and Azure, mostly because the ecosystem is really friendly and helps me focus on the right things.
I try to avoid unnecessary (a.k.a. accidental) complexity and in general everything that gets in the way of solving the essential complexity induced by the business needs.
This is why I favor a test-first approach to focus on the problem space and ask questions to business experts before even coding the feature.