(In order to not overload this already dense article, we assume you’re familiar with the notion of adapters in hexagonal architecture. We will also be using words like “mock” or “stub” interchangeably because the difference does not seem clear to anyone, as this interesting discussion on StackOverflow shows. Finally, on the technical side we use the NSubstitute library to create most of our mocks/stubs and NFluent for our test assertions).
As discussed in the previous article, our goal is to instantiate the highest level of our API such as an endpoint (a controller in our example) to pass the necessary inputs to run a real business scenario and to test the output of this endpoint. To avoid friction and test only our code, we will stub any interaction with the outside world:
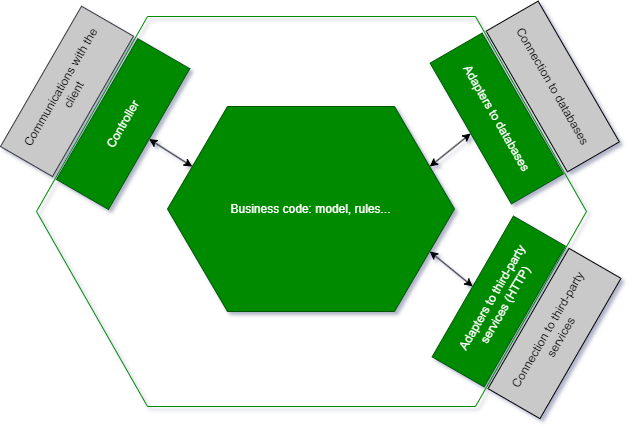
Depending on the technical stacks, instantiating an API while stubbing certain dependencies is not an easy task. Moreover we want to keep the technical aspects to a minimum in a test that must represent business behavior. Therefore we are going to try to get this boilerplate code out of the way. For our part, we have opted for a builder pattern using a somewhat “fluent” API, for better readability. The goal is that, should a business expert ever need to read the code, the intent would be immediately understandable.

Writing the test
In our case, we will start simply by writing a test that’s a little naive and doesn’t seem too cumbersome. For example let’s try counting the number of books returned by the GET method of the api/Catalog route. A first draft might be:
public class CatalogControllerShould
{
[Fact]
public async Task List_all_books_when_called_on_GetCatalog()
{
const int numberOfBooksInCatalog = 3;
var controller = new CatalogControllerBuilder()
.WithRandomBooks(numberOfBooksInCatalog)
.Build();
var catalogResponse = await controller.GetCatalog("EUR");
Check.That(catalogResponse.Books).HasSize(numberOfBooksInCatalog);
}
}The test code is clear and readable, the scenario is perfectly identifiable
It’s pretty straightforward. There’s not too much technical plumbing apart from the call to CatalogControllerBuilder. We want to create a CatalogController for a catalog containing 3 random books and check that the call to GetCatalog() returns the right number of books. We deliberately choose a number less than 5 here, as our site’s default pagination is 5 books. Baby steps! We will need to create another test with 6 or more books to check that the pagination feature works as expected.
Builder: first draft and introduction to fuzzing
Obviously the code does not compile since the builder code is missing. What is it going to look like? This is a bit complex. First of all, we have to create the controller with its dependencies and also make the stubs in the right places. Moreover, we are going to have to create random books. The random aspect is important here: we do not test the books themselves. We just want to be able to count them. So we are going to create them randomly instead of, say, hard-coding them : we call this technique fuzzing. To implement this, we’ll be using Thomas Pierrain’s Diverse library:
public class CatalogControllerBuilder
{
private readonly IFuzz _fuzzer = new Fuzzer();
private Book[] _booksInCatalog;
public CatalogControllerBuilder WithRandomBooks(int numberOfBooksToGenerate)
{
_booksInCatalog = Enumerable
.Range(0, numberOfBooksToGenerate)
.Select(_ => {
var randomIsbn = new ISBN.ISBN10(_fuzzer.GenerateInteger(1, 100), _fuzzer.GenerateInteger(1, 10000), _fuzzer.GenerateInteger(1, 1000), _fuzzer.GenerateInteger(1, 10));
var firstName = _fuzzer.GenerateFirstName();
var lastName = _fuzzer.GenerateLastName(firstName);
var authorName = $"{firstName} {lastName}";
var pictureUrl = new Uri(_fuzzer.GenerateStringFromPattern("http://picture-url-for-tests/xxxxxxx.jpg"));
return new Book(new BookReference(randomIsbn, _fuzzer.GenerateSentence(6), authorName, _fuzzer.GenerateInteger(10, 1500), pictureUrl), _fuzzer.GenerateInteger(1, 100));
})
.ToArray();
return this;
}
}Well, it’s a start, but it’s not very readable! An example of a judicious refactoring would be to make an extension method to IFuzz to generate ISBNs. There are also some implicit blind spots: each name is assumed to be in the “first name last name” format (which is wrong), integers are generated completely randomly to produce ISBNs, even though this may not be correct (we should ask a domain expert), and we assume that no more than 99 copies of a given book will be in stock. So we are kind of blinkered for this test, but it’s a starting point for our series of articles 😉
Let’s tackle the Build() method which will have to manage dependencies; again, it’s just a first draft to get the code to compile:
public CatalogController Build()
{
// spi ports are stubbed
var bookMetadataProvider = Substitute.For<IProvideBookMetadata>();
var inventoryProvider = Substitute.For<IProvideInventory>();
var bookAdvisorHttpClient = new BookAdvisorHttpClient(new HttpClient(new MockHttpHandler()));
// this port is not stub because of its dummy implementation
var bookPriceProvider = new BookPriceRepository();
// domain is created manually
var catalogProvider = new CatalogService(bookMetadataProvider, inventoryProvider);
// api adapter can be manually created since we have the domain and spi ports at hand
return new CatalogController(catalogProvider, bookPriceProvider, bookMetadataProvider, bookAdvisorHttpClient);
}Here, MockHttpHandler is a class that simply derives from HttpMessageHandler and returns an empty HttpResponseMessage. In short, it compiles but obviously crashes at runtime: as soon as we will try to read data from a port, the port will return null since no stub currently exists.
Stubs
The code compiles but the test crashes miserably when trying to read null data. Now let’s apply ourselves to making real stubs to make the test pass:
public class CatalogControllerBuilder
{
private readonly IFuzz _fuzzer = new Fuzzer();
private Book[] _booksInCatalog = Array.Empty<Book>();
public CatalogControllerBuilder WithRandomBooks(int numberOfBooksToGenerate)
{
_booksInCatalog = /* ... same code as above that generates books ... */
return this;
}
public CatalogController Build()
{
var bookMetadataProvider = StubBookMetadataProvider();
var inventoryProvider = StubInventoryProvider();
var bookAdvisorHttpClient = StubBookAdvisorHttpClient();
return /* create the domain & controller as before */
}
private IProvideInventory StubInventoryProvider()
{
var inventoryProvider = Substitute.For<IProvideInventory>();
inventoryProvider.Get(Arg.Any<IEnumerable<BookReference>>())
.Returns(callInfo =>
{
var requestedBookReferences = callInfo.Arg<IEnumerable<BookReference>>();
return _booksInCatalog.Where(book => requestedBookReferences.Contains(book.Reference));
});
return inventoryProvider;
}
private BookAdvisorHttpClient StubBookAdvisorHttpClient()
{
return new BookAdvisorHttpClient(new HttpClient(new MockBookAdvisorHttpHandler(_fuzzer))
{
BaseAddress = new Uri("http://fake-base-address-for-tests")
});
}
/* ... other stub methods matching the same pattern ... *
}The structure seems a little unwieldy. A lot of things are mixed up and a bit difficult to distinguish.
It’s cumbersome but not very complicated: we move the responsibility of stubbing each dependency into a dedicated method and make do in order to respond correctly. The MockBookAdvisorHttpHandler class for stubbing HTTP client behavior to BookAdvisor is also pretty straightforward:
internal class MockBookAdvisorHttpHandler(IFuzzNumbers fuzzer) : HttpMessageHandler
{
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
if (request.RequestUri is not null && request.RequestUri.AbsolutePath.StartsWith("/reviews/ratings/"))
{
var rating = Math.Round(fuzzer.GeneratePositiveDecimal(0m, 5m), 2);
var numberOfRatings = fuzzer.GenerateInteger(2, 20000);
return new HttpResponseMessage(HttpStatusCode.OK)
{
Content = JsonContent.Create(new RatingsResponse(rating, numberOfRatings))
};
}
return new HttpResponseMessage(HttpStatusCode.NotFound);
}
}First feedback
The test is now green; the complete code is available on the first commit of the “builders” branch. Let’s sit back and do a quick assessment, starting with the positives:
- The test code is clear and readable, the scenario is perfectly identifiable, and there’s virtually no purely technical code.
- We get all the benefits of an acceptance test: we replay a business scenario in the context of a complete call to our code outside the lower layers. With unit tests, we would have needed at least 5 or 6 different tests for the same scenario, stubbing several layers each time, with no guarantee that each brick would behave well with the others.
- As a result, we cover almost our entire stack with the exception of low layers such as
IProvideInventory(which is really a bit simplistic in our example). In the real world, in the case of a repository querying a database, we would be stubbing the DB connection rather than our port and its implementation. - The test is fast (around 130 to 150 ms on my Intel Core i7 8700k).
However, the structure seems a little unwieldy. A lot of things are mixed up (management and creation of dependencies, stub…) and a bit difficult to distinguish. It’s easy to imagine that if the code were to become even more complex, the builder would take on even more weight. Our builder simply reflects the complexity of our production code.
Improvements
We can come up with several solutions:
- Move the construction of each dependency to its dedicated builder. Here we go back to the principle of separation of concerns, where each component manages its own perimeter. In our example, this means having a
CatalogServiceBuilderthat manages the construction of its dependencies itself. - Use dedicated objects for fuzzing. For example, instead of using the
Bookbusiness object directly, we could use a “BookSpecification” object whose purpose would be to propose optional parameters where each unspecified parameter would be automatically fuzzed in the constructor. - Make our production code less complex! It seems obvious, but what appears to be a problem is in fact a good detector of code smells: if our builders are too complicated then maybe our production code is too and needs simplifying. This is a good opportunity to think about it.
Let’s try some of these ideas by improving our test: instead of simply counting the number of books, we will check that our API returns the right books by looking at each property.
We are not going to detail the whole implementation here; here’s what the test looks like and for the rest of the code (builders, etc…) you can refer to the second commit of the builders branch and see for yourself.
[Fact]
public async Task List_all_books_when_called_on_GetCatalog()
{
var fuzzer = new Fuzzer();
var books = new BookSpecification[]
{
new(fuzzer),
new(fuzzer),
new(fuzzer)
};
var controller = new CatalogControllerBuilder()
.WithBooks(books)
.Build();
var catalogResponse = await controller.GetCatalog("EUR");
Check.That(catalogResponse.Books).HasSize(books.Length);
// This because of the sloppy implementation of our BookPriceRepository :)
var uniqueBookPrice = new Price(8m, "EUR");
var expectedResponse = books.Select(book => new BookResponse(book.Isbn.ToString(), book.Title, book.Author, book.NumberOfPages, new RatingsResponse(book.AverageRating, book.NumberOfRatings), book.PictureUrl.ToString(), book.Quantity.Amount, uniqueBookPrice));
Check.That(catalogResponse.Books).IsEquivalentTo(expectedResponse);
}Feedback on the improved code
Pros
Again, if we were to criticise this new code, what could we say?
- The
CatalogControllerBuilderhas been slimmed down quite a bit! 49 lines compared to over 80 previously. This was one of the first objectives we had set. - Each builder is responsible for its own dependencies. The breakdown is clear and, to find out where a behaviour is stubbed, all we have to do is look in the corresponding builder.
- Similarly, dedicated objects are responsible for the construction of business objects and contain all the fuzzer manipulation. Builders no longer have to worry about it.
- Performance remains the same.
Cons
But these improvements have had other, negative impacts:
- The test is now more technical because the fuzzer had to be moved up in the test in order to create our
BookSpecifications. It is essential to use the same Fuzzer instance here in order to be able to reproduce bugs by setting a seed due to the random nature of fuzzing. As things stand, there’s not much we can do about this. As a matter of fact, our test in its current form crashes randomly… it’s up to you to debug and find out what’s wrong 😉 (hint: it’s when you generate an ISBN) - In essence, the structure becomes more complex as each dependency has its own builder. We didn’t have to make a builder for repositories which are simplistic here, but in more concrete cases of repositories connecting to databases, we would also have needed a builder for each repository in order to stub each connection to the database. If the number of dependencies increases, you will very quickly find yourself buried in several layers of builders that are difficult to understand and maintain.
- We have a shared dependency between 2 builders, introducing a coupling. Here,
IProvideBookMetadatais used by bothCatalogControllerandCatalogService. What should we do in our builders? I have chosen to make 2 different stubs in the spirit of partitioning each stub where it’s used, but we’re moving away from the behaviour of the production code where the dependency is declared with a Singleton scope inProgram.cs.Using the same instance in the stubs would make sense but would introduce time coupling in the builders, which would make our code even more complex.
Conclusion
As we can see, if the scope of the tests grows a little and we break down our technical boilerplate code, we end up with a correct breakdown but of increasing complexity. If our production code contained even more dependencies, it would quickly become difficult to find our way around. However, as we noted above, this also highlights the fact that the production code needs refactoring: is it really normal for our CatalogController to pass through a CatalogService in one case and use the BookMetadataProvider directly in the other?
In the next article, we will look in more detail at the situation we actually encountered on the backend of an e-commerce website where Benoît and I worked: where we started from, how the builders contributed and why we chose to go further.