Integration tests have always appeared as being slow and fragile. Slow because they imply launching APIs, network connections, database queries, etc… and fragile because any time a dependency is not available or data are modified then these tests might fail. Moreover, creating new data (e.g. with INSERTs in database) is impactful in a shared database instance.
However, we do need integration tests to supplement acceptance tests. Specifically, we need to test the interactions between our code and the external dependencies : JSON deserialization, database queries, etc… Luckily, new tools like Verify and Testcontainers can help us resolve some issues. Let’s see how to simplify integration testing in C# in 2025 !
Solving long multiple assertions
One of the issues with integration tests is that there can be quite a lot of assertions. If we want to be thorough, we have to check that the JSON returned by an HTTP call or the SELECT from a database actually returns everything they are supposed to.
Sample code !
I have created a dedicated repository for this article. It is an excerpt from the BookShop repository Benoît and I used for our “How to write meaningful tests” series ; it is simply the “list books in the catalog” scenario with a few adjustments here and there. For example, I added a PostgreSQL database to be run with Docker alongside the project. In the BasicIntegrationTests class, I have created the following test :
[Fact]
public async Task Should_return_all_7_books_from_database_without_Verify()
{
var options = new ConnectionStringsOptions { BookShopDatabase = "Server=localhost;Port=5432;User Id=postgres;Password=postgres;Database=bookshop;" };
var adapter = new BookDatabaseAdapter(Options.Create(options));
var books = await adapter.Get();
books.Count.ShouldBe(7);
books[0].Id.ToString().ShouldBe("978-133888319-0");
books[0].Author.ShouldBe("Tui T. Sutherland");
books[0].Title.ShouldBe("The Dragonet Prophecy (Wings of Fire #1)");
books[0].NumberOfPages.ShouldBe(336);
books[0].PictureUrl.ShouldNotBeNull();
books[0].PictureUrl!.AbsoluteUri.ShouldBe("https://s2.qwant.com/thumbr/0x0/5/4/3dde4aa99ad8275bf403c085737594fefa3a0c6b011359b3133c455df2570e/.jpg?u=http%3A%2F%2Fwww.scholastic.ca%2Fhipoint%2F648%2F%3Fsrc%3D9780545349239.jpg%26w%3D260&q=0&b=1&p=0&a=0");
books[1].Id.ToString().ShouldBe("978-054534919-2");
books[1].Author.ShouldBe("Tui T. Sutherland");
books[1].Title.ShouldBe("The Lost Heir (Wings of Fire #2)");
books[1].NumberOfPages.ShouldBe(296);
books[1].PictureUrl.ShouldNotBeNull();
books[1].PictureUrl!.AbsoluteUri.ShouldBe("https://s2.qwant.com/thumbr/0x380/6/7/99129d301bb33a6fe827579d3978bac1636ed3224b6278def5209446085b14/700.jpg?u=https%3A%2F%2Fembed.cdn.pais.scholastic.com%2Fv1%2Fchannels%2Fsso%2Fproducts%2Fidentifiers%2Fisbn%2F9780545349246%2Fprimary%2Frenditions%2F700%3FuseMissingImage%3Dtrue&q=0&b=1&p=0&a=0");
// etc...
}That’s quite a mouthful. And we are testing only 2 books, you can easily add 30+ lines for the other 5. Sure, we could refactor a few things but the test would remain clunky and difficult to read.
Snapshot testing 📸
There’s a technique called “snapshot testing” that can definitely help us with this. Snapshot testing is basically comparing the output of a test to a previously-recorded reference. We run the test for the first time, record its output, then every subsequent run of the test will check the output matches the recorded one. When the test fails, you can either fix a possible bug or replace the reference with the new output. Here’s a diagram showing the workflow :
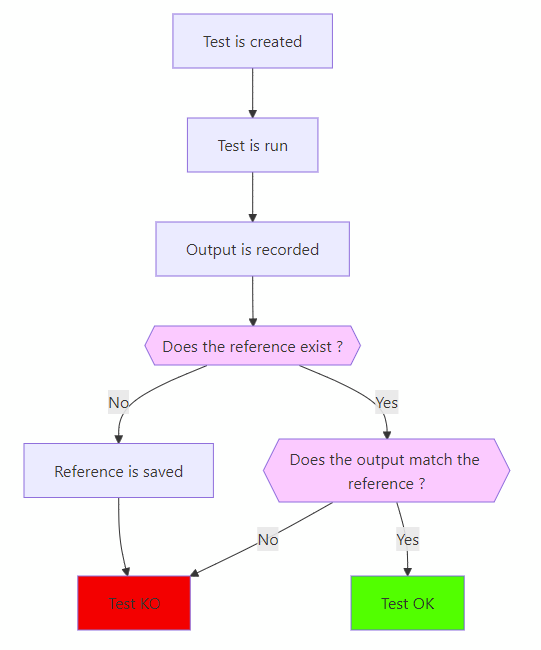
This is very useful to check complex or long outputs. How can we do that easily in .Net ?
Introducing Verify
Thanks to Simon Cropp, there is a library called Verify that does all the heavy lifting for us. It is very powerful and runs with most test frameworks. It will :
- serialize the output to a readable string,
- check the reference exists,
- perform the comparison,
- succeed or fail the test,
- open the computer’s default diff tool when the test fails.
There is also the possibility to specifically ignore or replace with a static value (“scrub”) some fields. By default, Verify will scrub various data types such as GUIDs and DateTimes. This is, of course, configurable.
Here’s what our test looks like when replacing all our manual checks with Verify :
[Fact]
public async Task Should_return_all_7_books_from_database()
{
var options = new ConnectionStringsOptions { BookShopDatabase = "Server=localhost;Port=5432;User Id=postgres;Password=postgres;Database=bookshop;" };
var adapter = new BookDatabaseAdapter(Options.Create(options));
var books = await adapter.Get();
await Verify(books);
}Much easier to read ! One could argue the test’s intention is lost. That’s true indeed but in our case, snapshot testing is not meant for specific intentions to be checked. More on that later.
So we can easily check queries to the database or HTTP calls. Good ! But that does not solve the main issues raised in introduction : fragility, context sharing and performance.
Using Testcontainers to mount dependencies locally
A recent tool that I was made aware of last year is Testcontainers. It provides libraries in various languages in order to mount containerized images directly from your test code : start your container engine, run your tests and voilà !
The major advantage is of course to be completely in control of your dependencies. You know they are up and running, you can write and delete data at will, you can run concurrent tests in different containers and each container will be disposed at the end of your tests. A complete (or partial) environment on demand, written in the same code as your tests.
Let’s see some code
In our previous test, we connected to the actual database by passing the real connection string. Now we will instantiate a containerized database with Testcontainers :
public readonly PostgreSqlContainer PostgreSqlContainer = new PostgreSqlBuilder()
.WithImage("postgres:latest")
.WithDatabase("bookshop")
.WithUsername("postgres")
.Build();That’s easy enough to read. This snippet will not start the container so we will have to do the following in a setup method :
await PostgreSqlContainer.StartAsync();Once the runner steps into a test, we will have a dedicated instance of our database just for us. We can connect to it by getting the connection string from the container. And we can throw in Verify to check the output :
[Fact]
public async Task Should_return_all_7_books_from_database()
{
var options = new ConnectionStringsOptions { BookShopDatabase = _postgreSqlContainer.GetConnectionString() };
var adapter = new BookDatabaseAdapter(Options.Create(options));
var books = await adapter.Get();
await Verify(books, _verifySettings);
}And that’s it. If we wanted to test book addition, here’s what we could do :
[Fact]
public async Task Should_add_a_book_into_database_and_return_all_8_books()
{
var options = new ConnectionStringsOptions { BookShopDatabase = _postgreSqlContainer.GetConnectionString() };
var adapter = new BookDatabaseAdapter(Options.Create(options));
var newBook = new Book(ISBN.Parse("978-0545685436"), "Talons of Power (Wings of Fire #9)", "Tui T. Sutherland", 336, new Uri("https://i.ebayimg.com/images/g/ydEAAOSwCU1YsXIS/s-l960.jpg"));
await adapter.Add(newBook);
var books = await adapter.Get();
await Verify(books, _verifySettings);
}We end up with robust automated integration tests running locally, in the same language as the rest of our tests.
Performance considerations
Creating and starting the PostgreSQL container takes 3 to 4 seconds on my computer (excluding the image pull which can take up to a minute). That’s not bad. However, when building the PostgreSqlContainer in our test class, we will create one container per test. So that’s 3-4 seconds per test. That might not be optimal, especially if our tests are independent and can safely be run alongside each other on a same database instance.
Therefore, we can put the code that initializes and starts the container into a one-time setup. With xUnit it’s called a ClassFixture and you can see it here. The test class uses this fixture and you’re good to go : each test will use the same container which will be instantiated only once.
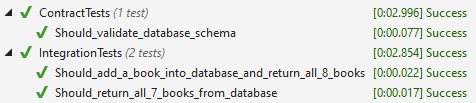
Database setup
One thing I haven’t mentioned is the database setup. Obviously, when creating a database instance from scratch, it will miss the schema and data we need to perform the tests. Therefore we will have to either restore an existing backup or create everything manually.
In the sample project, I favored using the former method. A backup script is stored in the Backups sub-folder of the test project and is restored in the InitializeAsync() method of the fixture. The code consists mainly in performing ExecScriptAsync() on the container object because PostgreSQL backup scripts are SQL scripts. I was able to do the same with SQL Server but it was more tedious.
Concurrent access
Another subject to be aware of is concurrent access. Sometimes you will want to have several tests running in parallel use the same database. Other times, because of unpredictability and race conditions (e.g. one test is writing into a table and the other is reading from it), you will want not to. This is when you want to pay attention to how your test framework handles parallelization. In xUnit v2’s case, there is a whole documentation about this topic.
In the sample project I chose not to do anything special : while they are sharing the same DB container, the tests located in the same class will run sequentially. This is xUnit’s default behavior and it suits the basic needs for this article. But you may want to separate concerns and create different classes for different contexts or be more explicit in the runner’s configuration.
Caveats

Use Verify only for some scenarios
While I really love Verify’s ability to clean up the test’s code, I would argue that it does it a bit too well. As I wrote previously, I think it hides the intentions behind the test : by removing the assertions, it is not entirely clear what we want to test. For the same reason, I would avoid using Verify in TDD scenarios when understanding the test’s intention is paramount. Note, however, that we could combine specific intentions in separate assertions and Verify in the same test.
No network check
Testcontainers is purely intended to test how our code behaves once connected to the dependencies. We will not check whether the network is OK (e.g. does our application have access to the dependencies ?). I typically rely on health checks deployed with the production code for that purpose.
Have a proper backup at hand
A point to consider when using containerized databases is to have a proper backup to restore. It should be recent enough so that you get the latest schema modifications. That means having access to this backup from local computers and build pipelines, which is not always easy. A good strategy is to see if your DBA can provide you with “previous business day” database images. They are a frequent practice so all you need is to be able to read them to restore them in your containers.
Performances considerations
Moreover, we are talking about setting up a container, meaning a virtual OS running a database server or a Redis or a RabbitMQ or… This has a non-negligible impact on performances. On my laptop, we are talking about a 3 to 6 seconds launch time for a PostgreSQL server. It would be insane to do it for every test. I will review a few techniques to improve all this in a follow-up post.
Conclusion
Even if there are still some limitations, I like the way integration testing in C# is going. We now have the ability to build reliable, repeatable, fast(-ish) integration tests ; we can test our adapters to our external dependencies without terrible boilerplate which is of tremendous help for readability.
Depending on the project, the point will be to find a balance between which dependency(-ies) must be called directly and which one(s) can be tested using a local Docker image. But that’s a saner question than going down the “I have to write integration tests, this is going to be a pain” path 😊