Note : la version anglaise de cet article est parue en décembre 2021, au moment où j’investiguais sur ce problème. Cette traduction française a quelques annés de retard donc il faut se remettre dans le contexte de l’époque 🙂
J’ai récemment dû investiguer une fuite mémoire détectée dans notre environnement de production. Les fuites mémoire sont en général un cauchemar pour beaucoup de développeurs :
- Il n’y a souvent pas de scénario de reproduction clair.
- Il faut être bien au fait des mécaniques internes de la gestion de la mémoire par notre langage de programmation (oui je sais « tous les développeurs devraient le savoir »).
- Les symptômes peuvent ne pas apparaître immédiatement mais après un certain temps, parfois comme un effet de bord.
- En revanche, une fois qu’ils sont visibles, les symptômes peuvent être très forts et mettre en danger tout l’environnement de prod.
Je ne suis pas un expert en gestion de mémoire ; toutefois, comme je connais un peu les mécanismes de garbage collection (ramasse-miettes en français) en C# et que j’ai un outil qui me permet d’investiguer, je vais essayer de récapituler dans cet article ce que j’ai appris au cours des jours précédents. J’espère que cela vous aidera à investiguer et réparer des fuites mémoire dans votre application .Net Core !
Contexte
Je travaille actuellement en tant que freelance pour un client du secteur hôtelier, essentiellement sur diverses API écrites en C# et déployées sous formes d’App Services dans Azure. Récemment, notre expert Azure (qui est aussi notre principal contact Ops) nous a signalé qu’ils devaient redéployer manuellement le backend principal de nos sites régulièrement parce qu’ils avaient eu plusieurs alertes de « seuil de mémoire atteint » de la part du système d’alerting Azure. Tous les X jours, ils avaient une alerte, redéployaient l’app service et tout rentrait dans l’ordre. Puis le problème se représentait quelques jours plus tard.
Au-delà de la solution simpliste du type « ajoutez plus de RAM sur les serveurs » qui aurait pu être valide dans un autre contexte, il était assez clair que nous devions trouver la cause du problème et la réparer.
Par où commencer ?
Mesures
La première chose à faire est de regarder les mesures dans Azure Portal. Voici à quoi ressemble le graphique de consommation mémoire :
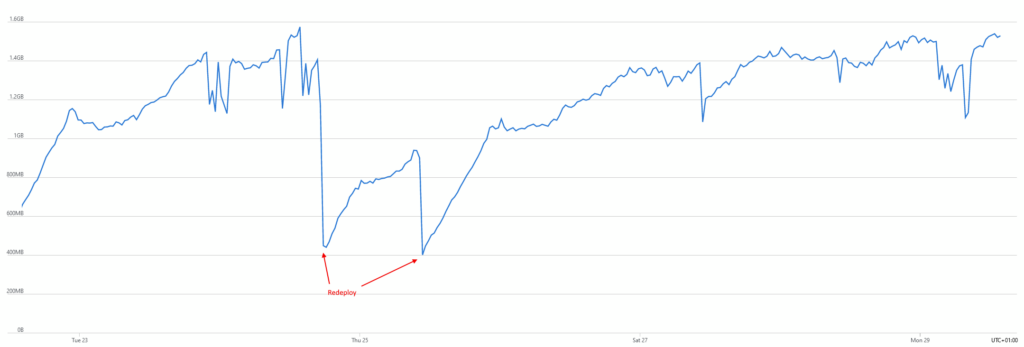
Notre train de release agissait donc comme un redéploiement régulier de notre API, ce qui relâchait la mémoire.
La fuite mémoire apparaît alors évidente : la consommation mémoire continue d’augmenter jusqu’à ce qu’elle atteigne un seuil correspondant aux limites du serveur. On peut voir des baisses ici et là mais elles ne sont pas suffisantes pour changer la hausse globale. La seule façon de nettoyer la mémoire est de relancer l’application ce qui, dans notre cas, était fait en redémarrant l’app service.
Le train de release
Comment se fait-il qu’on n’avait rien vu avant ? Les alertes sont en place depuis des années. Après quelques discussions, nous avons réalisé que c’était lié à la façon dont notre équipe travaille : le train de release. Tous les mardis, après synchronisation avec les équipes front, nous livrons une nouvelle version de notre backend en production. Sauf que ces dernières semaines nous travaillions sur une grosse migration de notre système de paiement et avons suspendu les déploiements en attendant de corriger les derniers bugs. Notre train de release agissait donc comme un redéploiement régulier de notre API, ce qui relâchait la mémoire retenue par la version précédente et ce jusqu’au mardi suivant. En fait il était très probable que la fuite mémoire était là depuis longtemps, c’est juste qu’elle ne nous impactait pas suffisamment pour faire sonner les alertes d’Azure. Peut-être que finalement ajouter de la RAM sur les serveurs aurait suffit ?
Quoi qu’il en soit, maintenant que j’y suis, autant essayer de corriger le problème pour de bon. Si jamais je ne trouve pas la cause racine ou que je ne parviens pas à la résoudre, on en rediscutera avec les experts Azure. Bref, maintenant qu’on sait qu’il y a une fuite mémoire, comment peut-on trouver ce qui ne va pas ?
Dumps mémoire
Un bon point de départ est de se procurer un dump mémoire, c’est-à-dire une sorte de photo de la mémoire utilisée par un processus à un instant T. En .Net Core, beaucoup d’informations sont stockées dans ces fichiers, ce qui peut les rendre intimidants voire inutiles sans outil adéquat. Visual Studio peut par exemple les ouvrir et les exploiter ; personnellement j’aime bien utiliser dotMemory de Jetbrains. Il n’est pas gratuit mais comme j’ai une licence pour tous les outils Jetbrains, je peux l’utiliser facilement.
Maintenant qu’on a le bon outil, il suffit juste de créer ces dumps. Dans Azure, il y a une chouette option qui permet de les générer en quelques clics (« Diagnose and solve problems » –> « Diagnostic tools » –> « Collect Memory Dump »), que ce soit par vous si vous avez les droits ou en demandant à vos experts ou admins Azure.
Première analyse
Ouvrons notre dump mémoire. Voici à quoi ressemble l’écran principal avec dotMemory une fois le fichier ouvert :
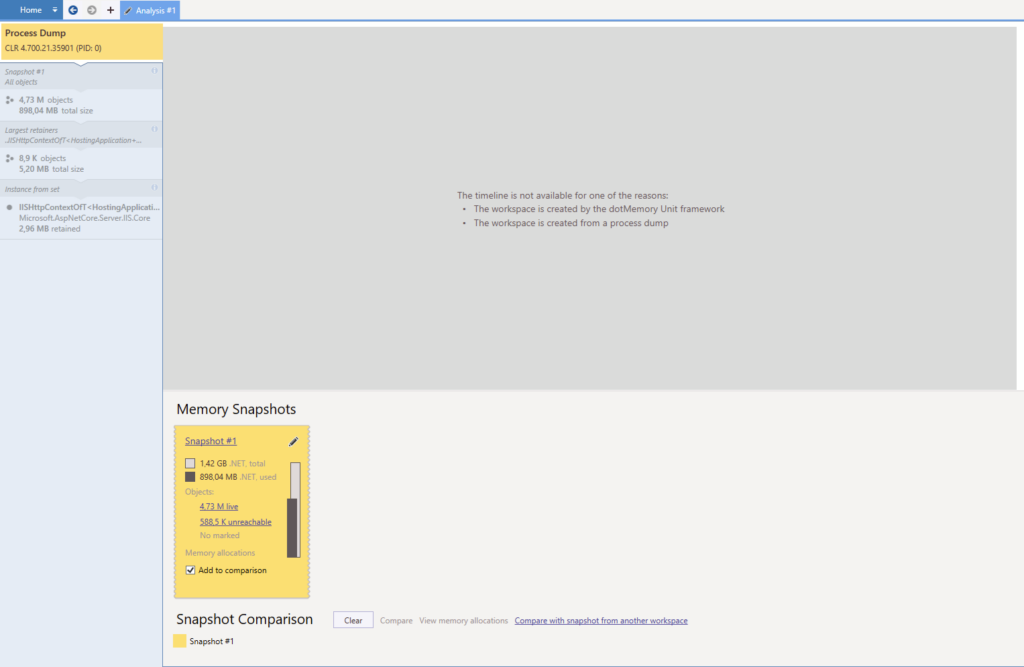
Et voici ce qu’il se passe quand on clique sur le lien « Snapshot #1 » situé dans le rectangle jaune :
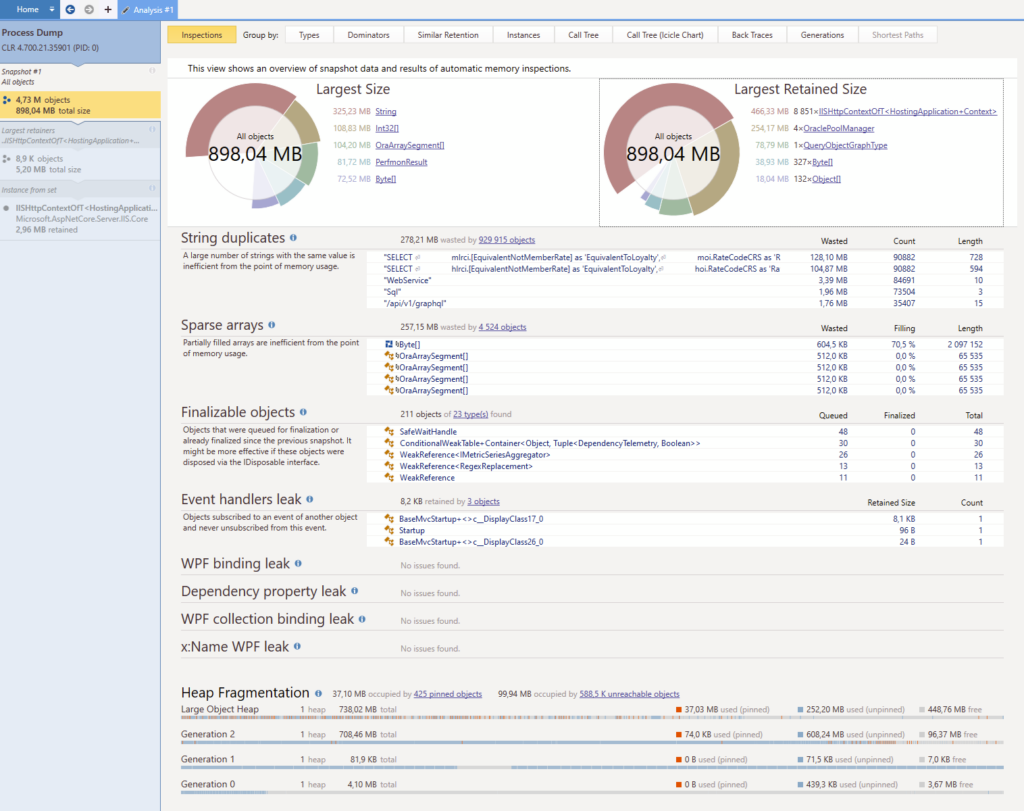
Plutôt intimidant hein ? Comme je disais plus haut, les dumps mémoire contiennent beaucoup d’informations, particulièrement celui-ci puisqu’il pèse un bon 2.4 Go. Toutes ces informations sont bonnes. Elles vont nous fournir des pistes voire des propositions qui nous aideront à déterminer où se situe le problème.
Premières impressions
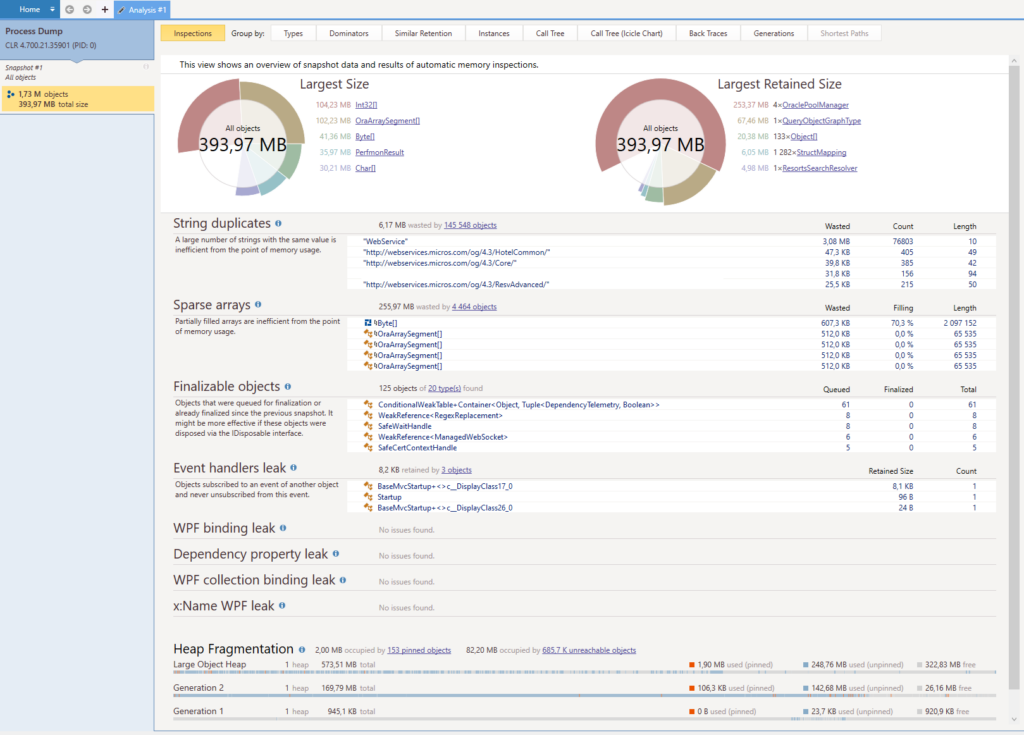
Afin de comprendre les sections principales de cet écran d’aperçu, il est important de lire la documentation de dotMemory. Il y a plusieurs points-clés dans cet écran :
- 2 types d’objets semble retenir plus de 75% de la mémoire : OraclePoolManager (4 instances) et IISHttpContextOfT<HostingApplication+Context> (8851 instances).
- Il y a 2 cas de duplication de chaînes de caractères et ils sont probablement assez simples à corriger.
- Beaucoup de mémoire est retenue au niveau de la la 2ème génération du garbage collector. Cela signifie qu’il y a une vraie fuite mémoire dans laquelle beaucoup d’objets sont considérés comme ayant un long cycle de vie.
Le sujet OraclePoolManager est connu ; on garde des connexions à notre base de données Oracle sous forme de singleton pour des questions de performance et donc le nombre d’objets internes au driver Oracle continue de grandir. Il faudra trouver une solution à terme mais ça ne semble pas être le gros du problème.
Pour l’instant, concentrons-nous sur le mystérieux IISHttpContextOfT<HostingApplication+Context>. Dans la suite de la narration, je vais utiliser un style peut-être moins formel et qui reflètera mon cheminement de pensée vers ce qui, je l’espère, sera une solution.
Creusons un peu
Bon. IISHttpContextOfT<HostingApplication+Context>. Je suis un peu perplexe parce que 1) je n’ai jamais rencontré ce type d’objet avant, 2) il a un nom super bizarre et 3) ça a l’air d’être un truc interne à IIS. Bien sûr j’ai déjà entendu parler d’HttpContext et on s’en sert d’ailleurs dans notre code par-ci par-là mais ça ne m’aide pas beaucoup. Et puis les recherches sur Internet ne sont pas très utiles. Qu’est-ce que je peux faire ?
Déjà, je remarque dans dotMemory que chaque nom de classe est souligné en bleu, donc ça signifie qu’on peut cliquer dessus. Voici ce que ça donne :
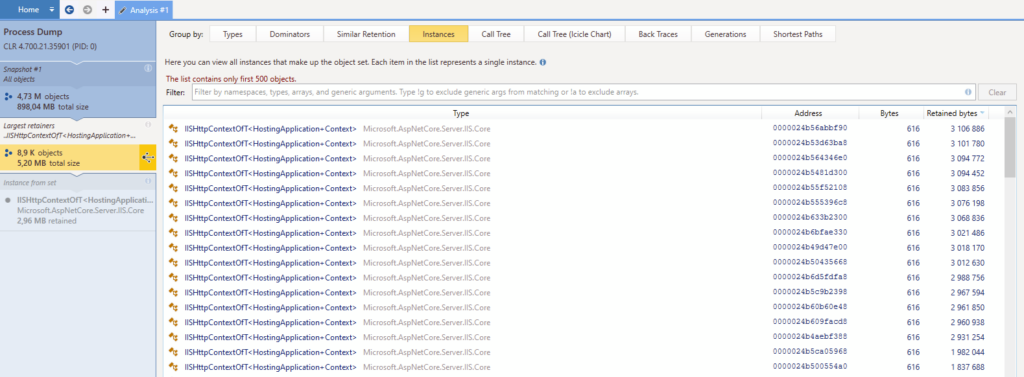
Bon donc j’ai une liste de toutes les instances et où elles se trouvent en mémoire. On voit un « Call Tree » dans les onglets du dessus, ça avait l’air intéressant mais ça ne donne rien dans notre cas. Ici encore, chaque instance est double-cliquable, donc c’est ce que je fais. Je tombe sur cet écran et je porte notamment un intérêt particulier à l’onglet « Key Retention Paths » :
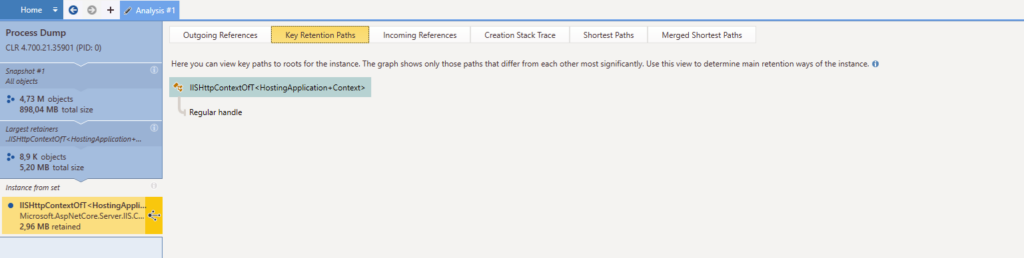
Bien essayé. Je m’attendais à voir une belle liste chaînée qui m’aurait montré quel(s) objet(s) retenai(en)t notre IISHttpContextOfT<HostingApplication+Context> en mémoire. Peut-être que j’aurais pu tomber sur un singleton que je n’aurais pas remarqué précédemment ou au moins un objet dans notre code que j’aurais pu reconnaître. Peine perdue.
Toutefois, il y a un onglet « Incoming References ». Cela pourrait m’aider à identifier quelque chose qiu me permettrait de réduire le périmètre de mes recherches ; voyons voir :
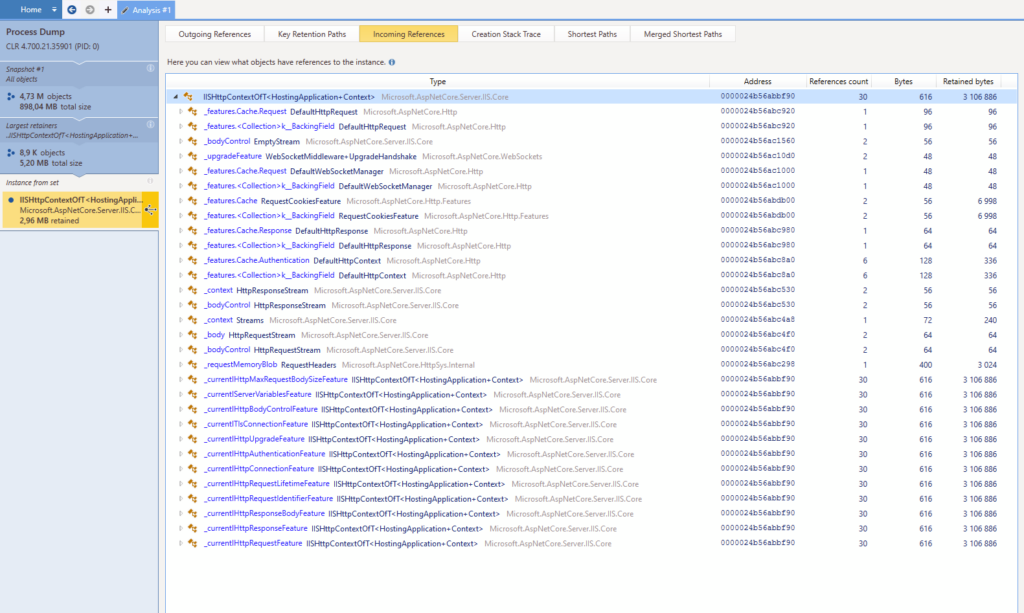
OK bon c’est pas génial mais c’est mieux que rien. Clairement je préfère avoir trop d’informations que pas assez. Ça n’aide pas énormément mais les mots-clés « WebSocket » et « Stream » retiennent mon attention. On a beaucoup (plusieurs dizaines de milliers, voire centaines de milliers) de connexions tous les jours sur nos sites et le fait que « seulement » 8851 objets sont retenus en mémoire après plusieurs jours suggère un scénario peu commun. Donc en mixant les mots-clés avec ce relativement petit chiffre, je me dis « et si c’était lié aux websockets ? ».
Ça se précise
Il n’y a que quelques scénarios où nous utilisons des websockets dans notre API et je le connais. Ce que je ne connais pas, c’est le code qui gère tout ça, enfin la partie infra, le code qui gère les websockets. Mais on doit sûrement utiliser une lib qui fait ça pour nous hein ? Hein ?
C’est le moment d’introduire un peu de contexte. On utilise beaucoup GraphQL dans notre API et les websockets sont utilisées uniquement pour tout ce qui est souscriptions. On utilise GraphQl.Net pour toute la plomberie, ce qui nous laisse nous occuper seulement du code des resolvers et des types. En revanche, pour les souscriptions, la documentation nous apprend que nous devons utiliser « un serveur qui supporte le protocole de subscription Apollo GraphQL », avec un lien vers un projet GraphQL Server. Allons voir ça chez nous. Oh oh. Tout ce qu’on a est une sorte de copier/coller d’une vieille version de GraphQL Server. Pas terrible.

Bon au moins les choses commencent à prendre forme. Peut-être qu’il y a une fuite dans ce code et que ça n’a pas été réparé parce qu’on ne l’a pas mis à jour avec la lib officielle ? C’est un peu maigre mais c’est ce que j’ai de mieux pour l’instant. Donc je commence à lire le code et les exceptions et fermetures de sockets semblent gérées correctement dans des clauses finally.
Je commence à me demander si je ne pourrais pas reproduire le problème localement. Je n’ai pas besoin de milliers de connexions pour remarquer une rétention de IISHttpContext. Donc je lance mon API en local avec IIS Express, j’attache dotMemory dessus et je commence à faire n’importe quoi avec les subscriptions GraphQL. Notamment à fermer des onglets ou carrément mon navigateur pendant que les données se chargent via les websockets. Par chance, on utilise les subscriptions pour des histoires de performance et qu’on a des scénarios où la websocket est sollicitée pendant 1 à 2 minutes. Donc ça me laisse du temps pour fermer les onglets manuellement.
Et ça marche !
On y arrive
Reproduction et automatisation
Après quelques essais, j’arrive finalement aux résultats suivants en local :
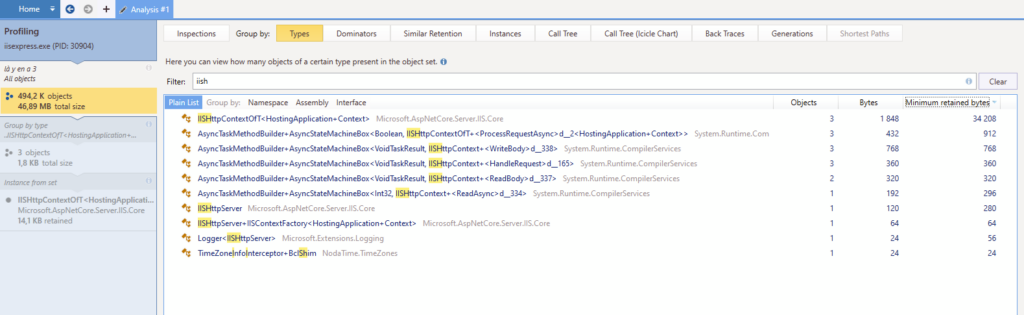
3 instances de IISHttpContextOfT sont retenues. Le scénario était en gros « ouvre la page, attends que la souscription commence à charger des trucs puis change de page en cliquant sur un lien ». Donc oui, ça semble lié à des fermetures un peu trop abruptes des websockets. Dans mon Visual Studio, on rencontre bien quelques WebSocketExceptions mais elles semblent correctement gérées par les blocs catch et finally donc je ne m’en fais pas trop.
Je chope aussi un petit bonus. Vous vous souvenez des « key retention paths » plus haut ? Les listes chaînées malheureusement un peu vides ? Eh bien avec mon dump mémoire local, elles sont beaucoup plus verbeuses :
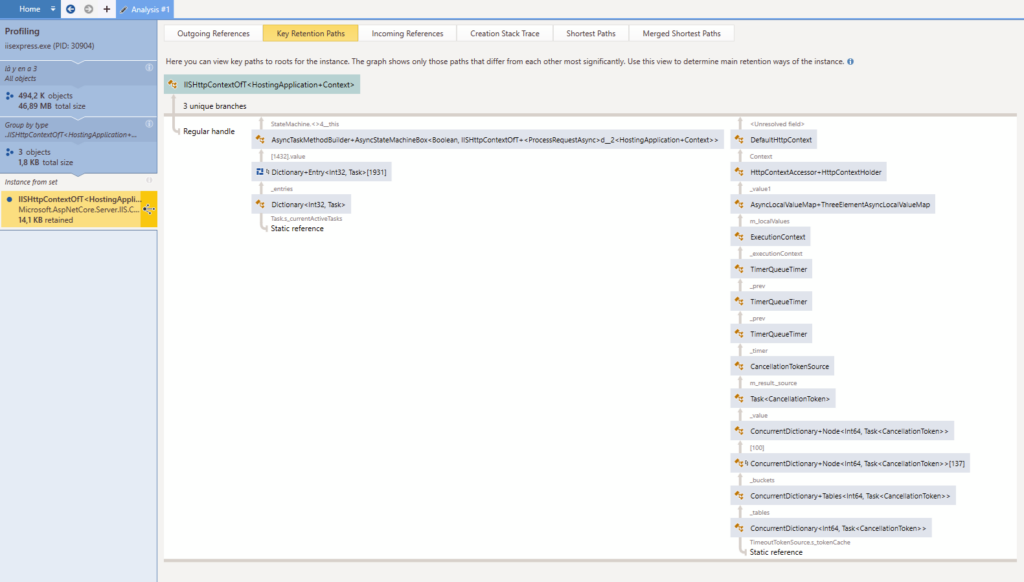
Au premier abord, il n’y a pas grand-chose ici qui va m’aider à trouver ce qui pourrait aller de travers avec mon code. Quelques dictionnaires dans un contexte async, d’autres dictionnaires, des timers… bouerf. Mais tous ces trucs async me poussent à retourner voir le code de gestion des websockets pour voir ce qui y est fait de façon asynchrone. Peut-être qu’il manque un mot-clé async quelque part et qui fait que les websockets ne sont pas toujours fermées comme il faut ?
Dans tous les cas, maintenant que j’ai un scénario de reproduction clair et déterministe, je l’automatise avec Gatling parce qu’il sait gérer les websockets aussi. Je peux donc reproduire le problème facilement ET rapidement, ce qui est un soulagement.
Tâches incomplètes
Je continue de lire le code qui gère les websockets et je tombe là-dessus :

On a un contexte async et on attend que quelque chose se complète avant d’appeler du code qui va probablement nettoyer des trucs. Un bon candidat pour mettre un point d’arrêt. Et en effet, le point d’arrêt est déclenché dans le cas où la websocket est fermée normalement par le client mais on n’y passe pas dans le cas d’une connexion avortée. Ça sent bon ! Au final, un peu plus loin dans la pile d’appel, je trouve le coupable :
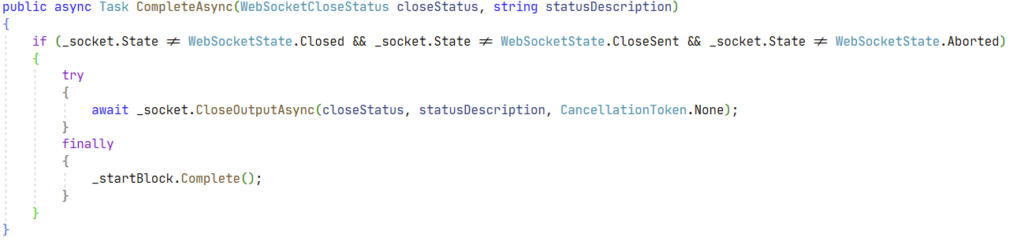
Dans le cas d’une déconnexion un peu sauvage, l’état de la socket est « Aborted ». Ce qui signifie que nous n’entrerons pas dans le bloc if, ce qui est une bonne chose pour éviter l’appel à CloseOutputAsync mais pas terrible pour la clause finally : la tâche _startBlock ne sera pas appelée sur la méthode Complete et restera probablement éternellement en mémoire. D’où tous mes problèmes. Après un fix rapide en local consistant en gros à ajouter une clause else dans le cas de l’état Aborted, la fuite mémoire semble avoir disparu.
Réparé !
Le correctif a été déployé en production la semaine dernière et le dernier dump memoire effectué 2 jours après la livraison montre que le problème a apparemment bien disparu :
Tout ce qui reste maintenant est le sujet avec l’OraclePoolManager pour lequel nous allons devoir trouver une solution pérenne mais ce n’est pas urgent. J’ai réfléchi à ouvrir une pull request au projet open source graphql-server mais cela aurait signifié reproduire le problème dans un environnement plus neutre et plus agnostique et je n’étais pas certain d’avoir le temps ou l’énergie. Donc j’ai plutôt ouvert un bug et il a été rapidement pris en compte par l’équipe du projet que je remercie chaudement au passage.
Conclusion
C’était une belle épopée. Lire tout ça en 10 minutes peut laisser croire que tout a été rapide. Ce n’était pas le cas. Cela m’a pris en tout 5 jours complets (moins quelques réunions) pour trouver un correctif. Je n’ai pas mentionné toutes mes erreurs, suppositions, appels à l’aide (grands mercis à Guillaume L, Nathanael et Pierrick de la communauté Okiwi !), essentiellement parce que c’était des problèmes spécifiques à mon contexte ou liés à mon manque de connaissances. Tout ce que j’ai appris de durable et réutilisable est dans cet article.
Quelques tuyaux :
- Prenez le temps de bien comprendre les bases de la garbage collection en .Net. Ce n’est pas très compliqué et cela vous aidera énormément à distinguer le bon grain de l’ivraie.
- Utilisez le bon outil pour l’analyse des dumps. Je n’ai employé que dotMemory ici et je ne peux pas faire de comparaison avec d’autres outils mais il est impératif d’en avoir un, ainsi que de bien lire sa documentation.
- Vous lirez bien plus de code que vous n’en écrirez. Au final, le correctif que j’ai livré faisait 5 lignes. J’ai aussi nettoyé 2-3 autres choses (coucou les doublons de chaîne de caractères) mais le gros du correctif faisait 5 lignes.
- Une fois que vous avez trouvé la fuite, concentrez-vous sur un scénario de reproduction et automatisez-le, de préférence en local. Ça m’a probablement économisé des heures de tests manuels inutiles.
- Lisez cet article. Il ne m’a pas aidé dans le cas présent mais il a porté à ma connaissance diverses bonnes et mauvaises pratiques en ASP .Net Core.
- Suivez votre instinct ! Certaines choses vous sembleront liées sans que vous puissiez le prouver ; essayez tout de même. C’est ce qu’il s’est passé quand j’ai relié HttpContext et WebSocket. Rien d’autre qu’une intuition mais cela s’est révélé fructueux.
Je mettrai cet article à jour si de nouveaux éléments se présentent. D’ici-là, soyez prudents.

Software developer since 2000, I try to make the right things right. I usually work with .Net (C#) and Azure, mostly because the ecosystem is really friendly and helps me focus on the right things.
I try to avoid unnecessary (a.k.a. accidental) complexity and in general everything that gets in the way of solving the essential complexity induced by the business needs.
This is why I favor a test-first approach to focus on the problem space and ask questions to business experts before even coding the feature.