Dans le précédent article, nous avons vu comment paralléliser des appels séquentiels. Aujourd’hui, je souhaite adresser un sujet similiaire du point de vue algorithmique : trouver et optimiser les problèmes de performances en C#. Et en particulier les allocations de chaînes de caractères et les ordres de complexité temporelles algorithmiques (O(n), O(n²), O(log n), etc…).
Un peu d’histoire
Comme dans l’article précédent, j’investiguais des sujets de performances vers mai 2023. Après avoir corrigé quelques problèmes liés à nos dépendances, je voulais regarder comment se comportaient nos APIs en production. Je pouvais évidemment compter sur la vue Performances dans Application Insights pour me donner un aperçu par route et même me permettre de voir ce que donnait chaque dépendance. Mais il me manquait une vue en interne me disant quelles parties du code sollicitaient un peu trop le CPU ou la mémoire.
Le profiler d’Application Insights
Après une discussion rapide avec notre expert Azure, j’ai vu que nous pouvions activer un profiler directement dans Azure. Ce profiler a un coût non négligeable, donc l’activer aurait des répercussions sur les performances de nos sites. Donc nous nous sommes mis d’accord pour l’activer sur une courte période, voir comment tout se comportait et décider ensuite si on réitèrerait l’approche.
Nous avons fini par l’activer pendant quelques heures par jour pendant quelques jours. Cela m’a donné accès à la page des optimisations de code qui liste des problèmes potentiels observés par Azure pendant que le profiler était activé.
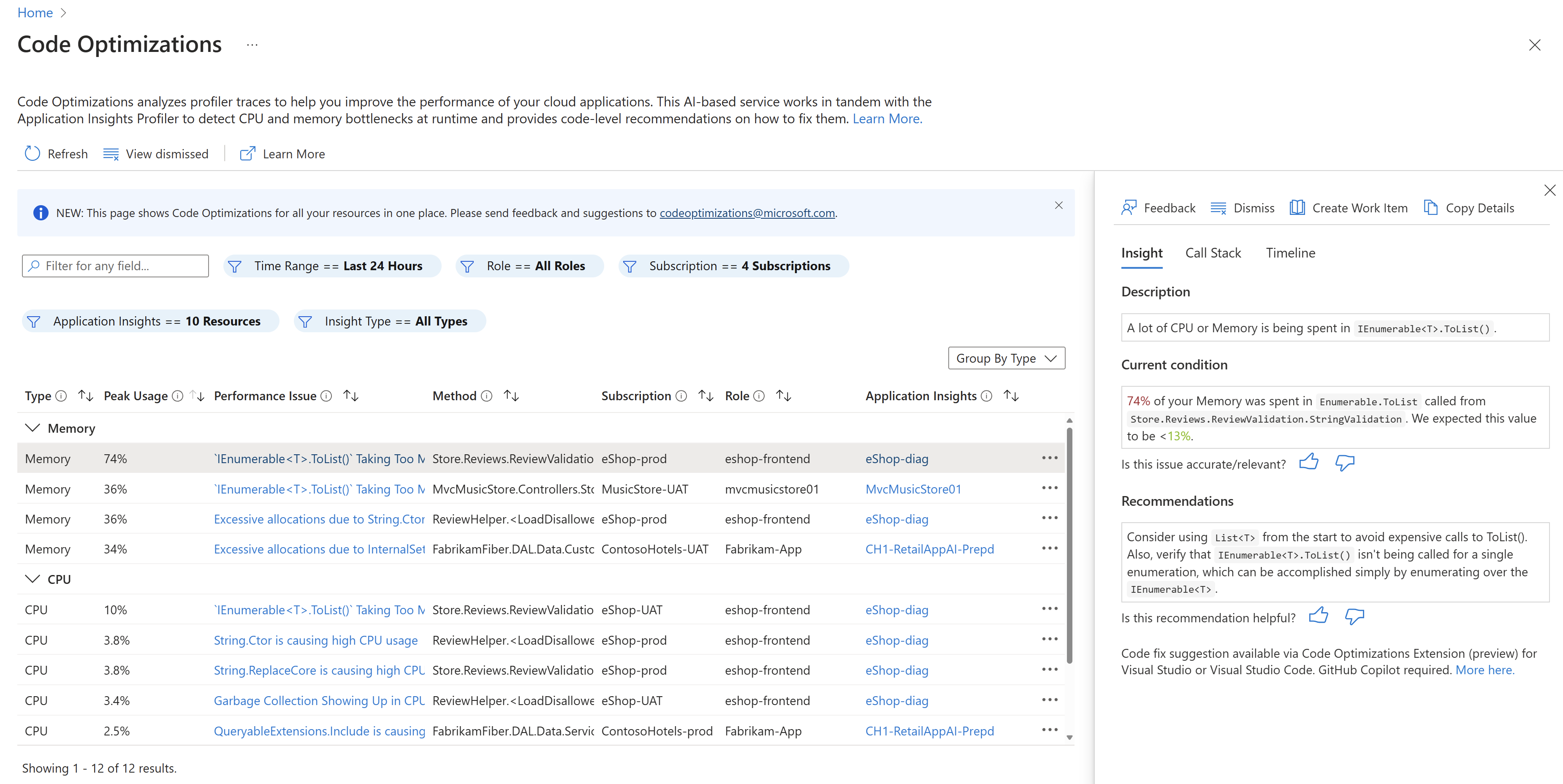
Premières découvertes
En haut de la liste figuraient des choses sur lesquelles je n’avais aucun contrôle : désérialisation d’appels à la base de données, task scheduler de GraphQL, Regex (faites attention à bien suivre les bonnes pratiques lorsque vous les utilisez), etc… Toutefois, j’ai fini par trouver quelque chose de bizarre qui allouait pas mal d’objets et prenait aussi du temps CPU 🤔 J’ai regardé le code et…
public static string? GetTranslation(IEnumerable<TranslationCacheDto> translations, string itemName)
{
return translations.FirstOrDefault(t => $"cache.key.{itemName?.Replace("/\\s/g", "").ToLower()}".Equals(t.CacheKey, StringComparison.InvariantCultureIgnoreCase))?.TranslatedText;
}Le moins qu’on puisse dire c’est que c’est le bazar et à l’origine c’était sur une seule ligne. Comme je l’ai appris avec le temps, c’est généralement une bonne idée de découper les « one-liners » pour mieux les comprendre. Dans notre cas, le gros de la logique est située dans le prédicat du FirstOrDefault(). Voici grosso modo ce qu’il fait :
- Remplace quelque chose dans la variable
itemNamedonnée en paramètre ; - Puis la convertit en minuscule ;
- Puis l’ajoute par interpolation à la fin de la chaîne « cache.key. » ;
- Puis compare cette valeur avec la propriété
CacheKeyde chaque traduction en ignorant la casse et en utilisant la culture invariante ; - Enfin, renvoie la propriété
TranslatedTextde la première traduction correspondante ou null.
Premières pistes
Plusieurs choses me viennent à l’esprit :
- Utiliser
ToLower()et comparer avecInvariantCultureIgnoreCasedonnent le même résultat. Donc on peut déjà supprimer cet appel àToLower()et garder le comparateur. Cela nous débarrasse d’une allocation de chaîne inutile effectuée à chaque itération duFirstOrDefault(). - De la même manière, la concaténation de chaîne via interpolation est effectuée à chaque itération elle aussi. On peut faire cette interpolation en-dehors du
FirstOrDefault()pour un gain non négligeable en allocation mémoire. - Cet appel à
String.Replace()a l’air chelou. On dirait que le développeur d’origine a voulu passer une Regex pour supprimer les espaces… sauf queString.Replace()ne sait pas gérer les expressions régulières. Pour ce que ça vaut, j’ai vérifié en base de données et aucun item ne contient la chaîne « /\s/g ».
On dirait qu’on peut améliorer les choses facilement ici ! J’ai ajouté quelques tests pour être sûr que je ne cassais rien et j’ai fait mes modifications. Mais comment être sûr que je réparais vraiment quelque chose ?
Code d’exemple !
Implémentons le code original et le code « corrigé »
La première analyse a l’air prometteuse sur le papier mais testons-la. Pour ce faire, j’ai créé un repository dédié ; n’hésitez pas à y jeter un oeil. La classe BadImplem est celle qui contient l’algorithme original. La classe ImprovedImplem contient les améliorations listées plus haut, ce qui nous donne le code suivant :
public static string? GetTranslation(IEnumerable<TranslationCacheDto> translations, string itemName)
{
var key = $"cache.key.{itemName}";
return translations
.FirstOrDefault(translation => key.Equals(translation.CacheKey, StringComparison.InvariantCultureIgnoreCase))
?.TranslatedText;
}Est-il possible de l’améliorer encore ? Le but de cet algorithme semble être de chercher une valeur spécifique puis de la renvoyer. En itérant sur une liste et en comparant chaque élément, la complexité temporelle de l’algorithme est en O(n). En pratique, itérer de temps en temps sur 10 éléments d’une liste n’aura pas de grande incidence d’un point de vue des performances. Mais en regardant les vrais chiffres sur notre environnement de production, il est apparu que la liste contenait plus de 50 000 éléments et que l’algorithme était utilisé plusieurs fois par seconde. Ce n’est pas bon, ces améliorations ne seront peut-être pas suffisantes.

Penser en O(1)
On est sur un cas où je vais penser immédiatement à utiliser un Dictionary. Retrouver un élément dans un Dictionary a une complexité temporelle en O(1), ce qui est la façon la plus rapide. Il y aura en revanche une contrepartie lors de la création du Dictionary donc il faudra la mesurer aussi. Quoi qu’il en soit, j’ai ajouté le code suivant pour construire le Dictionary dans Program.cs :
void InitializeDictionary(Dictionary<string, string> dictionary, TranslationCacheDto[] translationDtos, string[] itemNames)
{
for(var i = 0; i < 50000; i++)
{
dictionary.Add(itemNames[i], translationDtos[i].TranslatedText);
}
}Et le code trivial suivant pour lire depuis le Dictionary :
public static string GetTranslation(IDictionary<string, string> translationsByItemName, string itemName)
{
return translationsByItemName[itemName];
}Mesures
OK, nous allons maintenant voir comment comparer ces 3 approches entre elles. Regardez le contenu de Program.cs. En gros, une fois que les données et le dictionnaire sont en place, nous essaierons de trouver une valeur aléatoire 1000 fois d’affilée. Puis nous regarderons combien de CPU aura été consommé et combien d’allocations mémoire auront été effectuées pendants ces opéarions.
On compile en mode Release, on appuie sur Alt+F2 dans Visual Studio, on choisit le profiler « CPU Usage » eeeeet…
Utilisation CPU
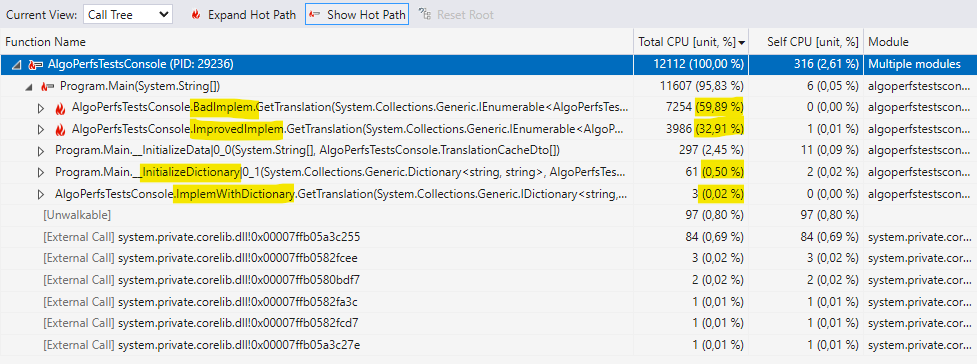
Voilà. On peut maintenant dire avec une certaine confiance que la première implémentation corrigée divise quasiment par 2 l’utilisation CPU.
Quoi d’autre ? Évidemment l’implémentation en O(1) bat tout le monde les mains dans les poches. Même construire le Dictionary ne représente qu’une fraction du coût des 2 autres approches. Construire le Dictionary ET y chercher des valeurs aléatoires prend 1% du coût de la version originale ! C’est donc la meilleure méthode ? Pas si vie, regardons d’abord les allocations mémoire. (Note : afin de réduire la durée d’analyse, j’ai baissé le nombre d’éléments de 1000 à 200).
Allocations mémoire
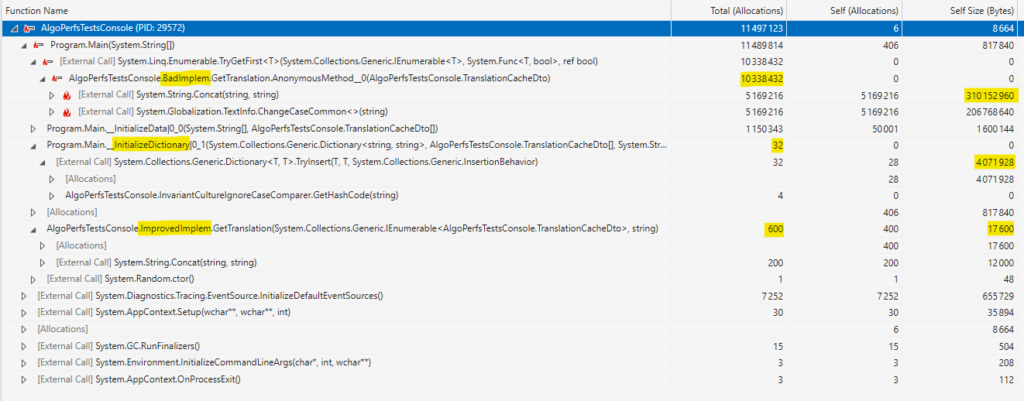
En effet, l’initialisation du Dictionary alloue très peu d’objets (bien sûr, les TranslationDtos étaient déjà créés par InitializeData()). Mais il consomme une quantité non négligeable de mémoire avec près de 4 Mo. En revanche, ImprovedImplem a très peu d’allocations ET ne consomme quasiment pas de mémoire.
Conclusion
Quelle conclusion peut-on donc tirer de tout cela ? Comme beaucoup de réponses dans le développement logiciel, « ça dépend« . Bien sûr, la première implémentation n’était pas optimale donc il est probablement préférable de choisir l’une des deux autres. Mais laquelle ? Chaque solution a ses avantages et inconvénients et je n’ai proposé ici que 2 solutions.
Si vous vous retrouvez dans un contexte où vous devez reconstruire le Dictionary de 0 à chaque requête et que la mémoire que vous pouvez utiliser est limitée, alors ImprovedImplem en O(n) mérite d’être prise en considération. Mais si les ressources CPU sont un sujet et qu’un usage temporaire de 4 Mo de mémoire n’est pas un souci, alors j’utiliserais probablement l’implémentation à base de Dictionary.
Une autre leçon importante à tirer ici est : faites très attention à chaque fois que vous manipulez des chaînes de caractères et que vous les comparez ! Les chaînes de caractères sont immutables, donc chaque modification créera de nouvelles instances, ce qui requiert beaucoup d’allocations mémoire.
J’ai à peine effleuré la surface de ce qui peut être accompli avec des profilers. L’idée était de vous donner un aperçu de code basique ainsi qu’une introduction rapide aux outils disponibles. J’espère que cela vous aura été utile ! Pour aller plus loin, on s’intéressera à la librairie BenchmarkDotNet qui permet de faire tourner des benchmarks et des mesures poussées simplement.

Software developer since 2000, I try to make the right things right. I usually work with .Net (C#) and Azure, mostly because the ecosystem is really friendly and helps me focus on the right things.
I try to avoid unnecessary (a.k.a. accidental) complexity and in general everything that gets in the way of solving the essential complexity induced by the business needs.
This is why I favor a test-first approach to focus on the problem space and ask questions to business experts before even coding the feature.